AMD's Steamroller Detailed: 3rd Generation Bulldozer Core
by Anand Lal Shimpi on August 28, 2012 4:39 PM EST- Posted in
- CPUs
- Bulldozer
- AMD
- Steamroller
Today at the annual Hot Chips conference, AMD’s new CTO Mark Papermaster unveiled the first details about the Steamroller x86 CPU core.
Steamroller is the third instantiation of AMD’s Bulldozer architecture, first conceived in the mid-2000s and finally brought to market in late 2011. Committed to this architecture for at least one more design after Steamroller, AMD has settled on roughly yearly updates to the architecture. For 2012 we have the introduction of Piledriver, the optimized Bulldozer derivative that formed the CPU foundation for AMD’s Trinity APU. By the end of the year we’ll also see a high-end desktop CPU without processor graphics based on Piledriver.
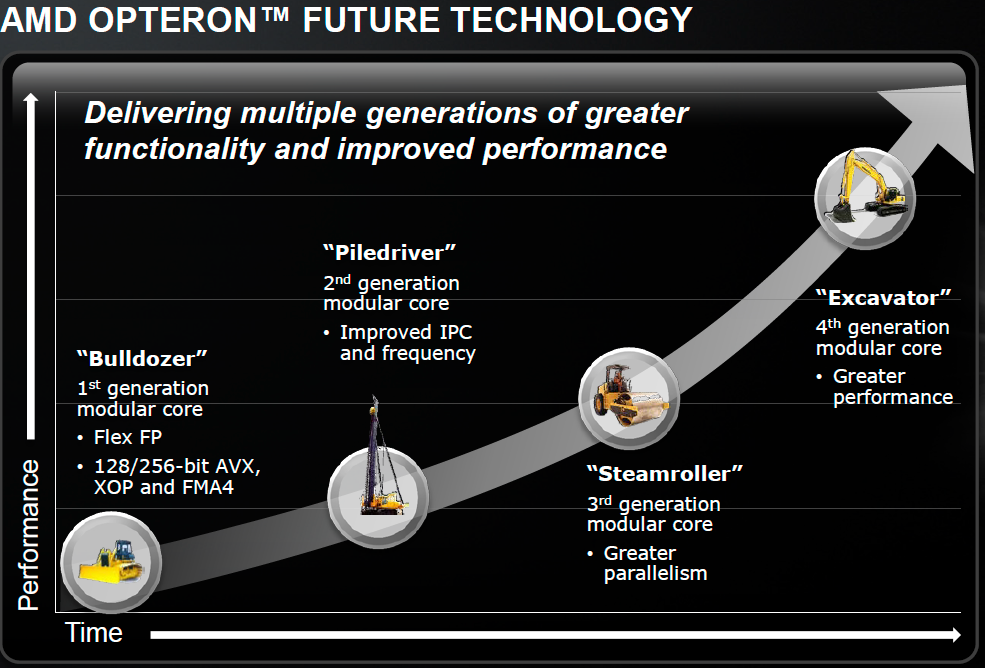
Piledriver saw a switch to hard edge flip flops, which allowed for a considerable decrease in power consumption at the expense of careful design and validation work. Performance didn’t change, but AMD saw a 10% - 20% reduction in active power. Piledriver also brought some scheduling efficiency improvements, but prefetching and branch prediction were the two other major design improvements in Piledriver.
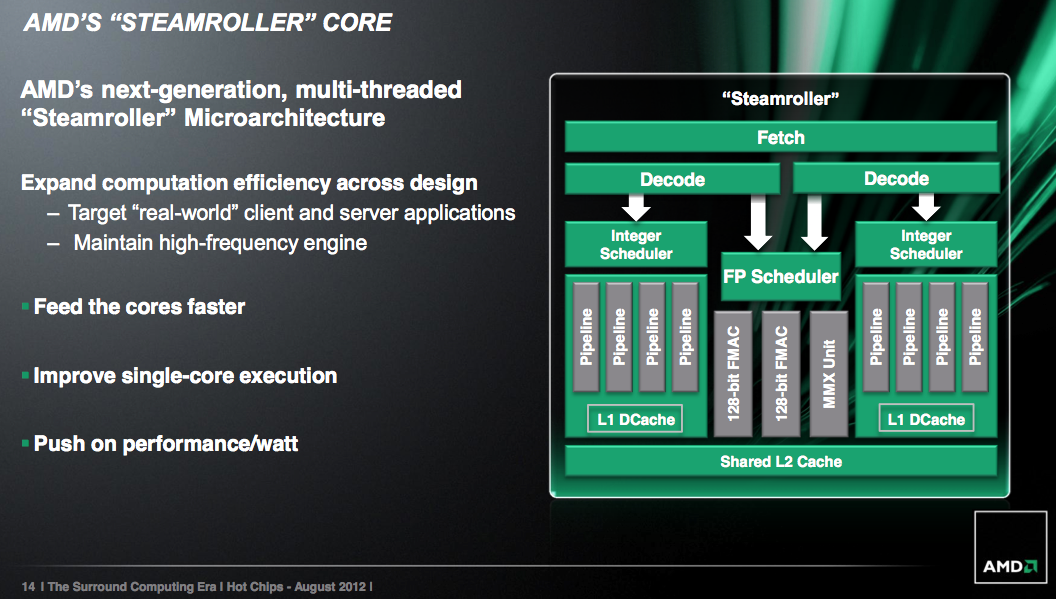
Steamroller is designed to keep the ball rolling. It takes fundamentals from the Bulldozer/Piledriver architectures and offers a healthy set of evolutionary improvements on top of them. In Intel speak Steamroller wouldn’t be a tick as it isn’t accompanied by a significant process change (28nm bulk is pretty close to 32nm SOI), but it’s not a tock as the architecture is mostly enhanced but largely unchanged. Steamroller fits somewhere in between those two extremes when it comes to changes.
Front End Improvements
One of the biggest issues with the front end of Bulldozer and Piledriver is the shared fetch and decode hardware. This table from our original Bulldozer review helps illustrate the problem:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
Steamroller addresses this by duplicating the decode hardware in each module. Now each core has its own 4-wide instruction decoder, and both decoders can operate in parallel rather than alternating every other cycle. Don’t expect a doubling of performance since it’s rare that a 4-issue front end sees anywhere near full utilization, but this is easily the single largest performance improvement from all of the changes in Steamroller.
The penalties are pretty obvious: area goes up as does power consumption. However the tradeoff is likely worth it, and both of these downsides can be offset in other areas of the design as you’ll soon see.

Steamroller inherits the perceptron branch predictor from Piledriver, but in an improved form for better performance (mostly in server workloads). The branch target buffer is also larger, which contributes to a reduction in mispredicted branches by up to 20%.
Execution Improvements
AMD streamlined the large, shared floating point unit in each Steamroller module. There’s no change in the execution capabilities of the FPU, but there’s a reduction in overall area. The MMX unit now shares some hardware with the 128-bit FMAC pipes. AMD wouldn’t offer too many specifics, just to say that the shared hardware only really applied for mutually exclusive MMX/FMA/FP operations and thus wouldn’t result in a performance penalty.
The reduction of pipeline resources is supposed to deliver the same throughput at lower power and area, basically a smarter implementation of the Bulldozer/Piledriver FPU.
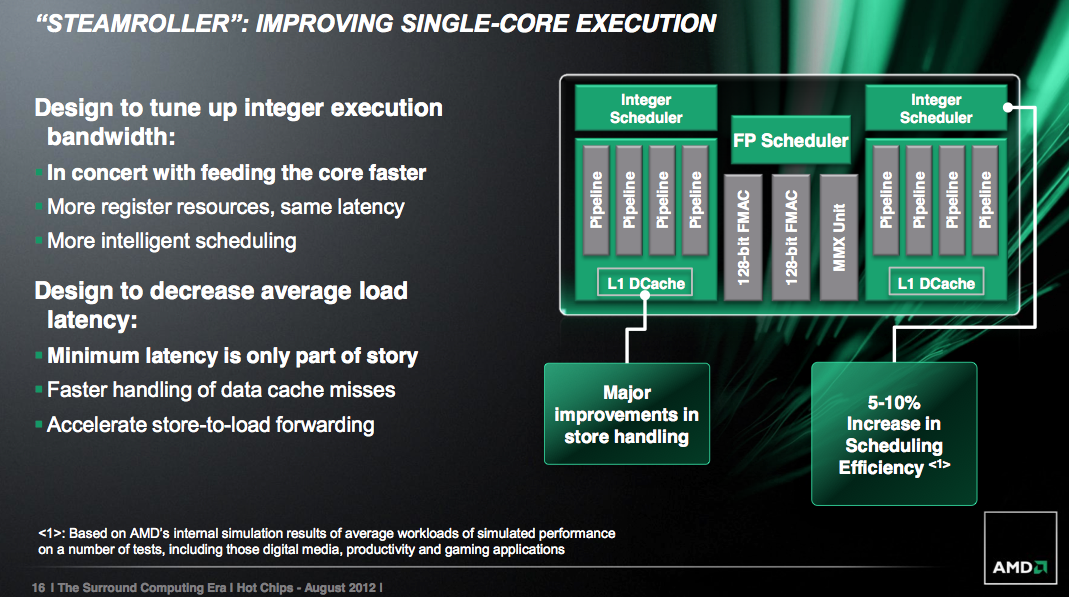
There’s no change to the integer execution units themselves, but there are other improvements that improve integer performance.
The integer and floating point register files are bigger in Steamroller, although AMD isn’t being specific about how much they’ve grown. Load operations (two operands) are also compressed so that they only take a single entry in the physical register file, which helps increase the effective size of each RF.
The scheduling windows also increased in size, which should enable greater utilization of existing execution resources.
Store to load forwarding sees an improvement. AMD is better at detecting interlocks, cancelling the load and getting data from the store in Steamroller than before.








126 Comments
View All Comments
mantikos - Tuesday, August 28, 2012 - link
This is what Buldozer should've been from the get go pretty muchCeriseCogburn - Wednesday, August 29, 2012 - link
So they're going to build..First they Bulldoze the place
Then they bring in the Piledriver laying the postings
Then the Steamroller for the building surroundings
Next comes Excavator ! to destroy all the former work
Great plan amd...
shtldr - Thursday, August 30, 2012 - link
And then will come the ultimate AMD CPU, called Undertaker, and bury the company once and for all.rarson - Tuesday, September 18, 2012 - link
Yeah, because screw competition. I want crappy products at high prices. Long live Intel!MrSpadge - Wednesday, August 29, 2012 - link
It looks really promising, indeed. Lot's of fine tuning there, actually more than just "fine". And they don't need to beat Intel for top performance anyway, just keep up the pressure and give us good mainstream chips with solid single thread performance!CeriseCogburn - Wednesday, August 29, 2012 - link
That's what they get beat on all the time, single thread performance - oh and multi thread for that matter.They've been getting creamed on single thread, specifically.
Your exclamation point sure points to a fine fantasy never happening future though given the failure that the present is.
Must take a lot of fanboyism and some strong prozac in the water.
Spunjji - Thursday, August 30, 2012 - link
Anyone would think that seeing as he's *hoping* for better single-thread performance, that he thus knows *they don't have it now*. But no. You didn't.Must take being a catastrophic ass-hat and some serious piss on your chips for you to jump on somebody for a completely inoffensive post.
CeriseCogburn - Friday, October 12, 2012 - link
Oh, from the uker amd fanboy where prozac is in the water, who prays to god for a return to what he misses about amd.News flash idiot: no one pisses on chips here. That's done where you live.
Now : " just keep up the pressure and give us good mainstream chips with solid single thread performance! "
Anyone with a brain would think we're already there, and will continue to be, pissy boy.
d3mag0gu3 - Tuesday, April 2, 2013 - link
Lol dude. You sound about three years old. Go sit in the corner until you can participate in class properly.redwarrior - Sunday, March 31, 2013 - link
Less and less applications are single-threaded, it's a dying part of the market. AMD is every bit as goodas Intel and better in its price class. Most apps perform betteron FX-8350 than I5 3570k. The FPS are up there with 3770k on many new games. This will only get better over the next year as more and more games offer 8 core processor support. There is absolutely no compelling reason to go Intel for cpu's under $300. With Steamroller the ascension of AMD to a BETTER alternative to Intel will only accelerate. All the initial bad reviews which were based on erroneous testing procedures and old benchmarks are proving to be ancient history and poor analysis