Intel's Xeon E5-2600 V2: 12-core Ivy Bridge EP for Servers
by Johan De Gelas on September 17, 2013 12:00 AM ESTWhat Has Improved?
Ivy Bridge is what Intel calls a tick+, a transition to the latest 22nm process technology (the famous P1270 process) with minor architectural optimizations compared to predecessor Sandy Bridge (described in detail by Anand here):
- Divider is twice as fast
- MOVs take no execution slots
- Improved prefetchers
- Improved shift/rotate and split/Load
- Buffers are dynamically allocated to threads (not statically split in two parts for each thread)
Given the changes, we should not expect a major jump in single-threaded performance. Anand made a very interesting Intel CPU generational comparison in his Haswell review, showing the IPC improvements of the Ivy Bridge core are very modest. Clock for clock, the Ivy Bridge architecture performed:
- 5% better in 7-zip (single-threaded test, integer, low IPC)
- 8% better in Cinebench (single-threaded test, mostly FP, high IPC)
- 6% better in compiling (multi-threaded, mostly integer, high IPC)
So the Ivy Bridge core improvements are pretty small, but they are measureable over very different kinds of workloads.
The core architecture improvements might be very modest, but that does not mean that the new Xeon E5-2600 V2 series will show insignificant improvements over the previous Xeon E5-2600. The largest improvement comes of course from the P1270 process: 22nm tri-gate (instead of 32nm planar) transistors. Discussing the actual quality of Intel process technology is beyond our expertise, but the results are tangible:
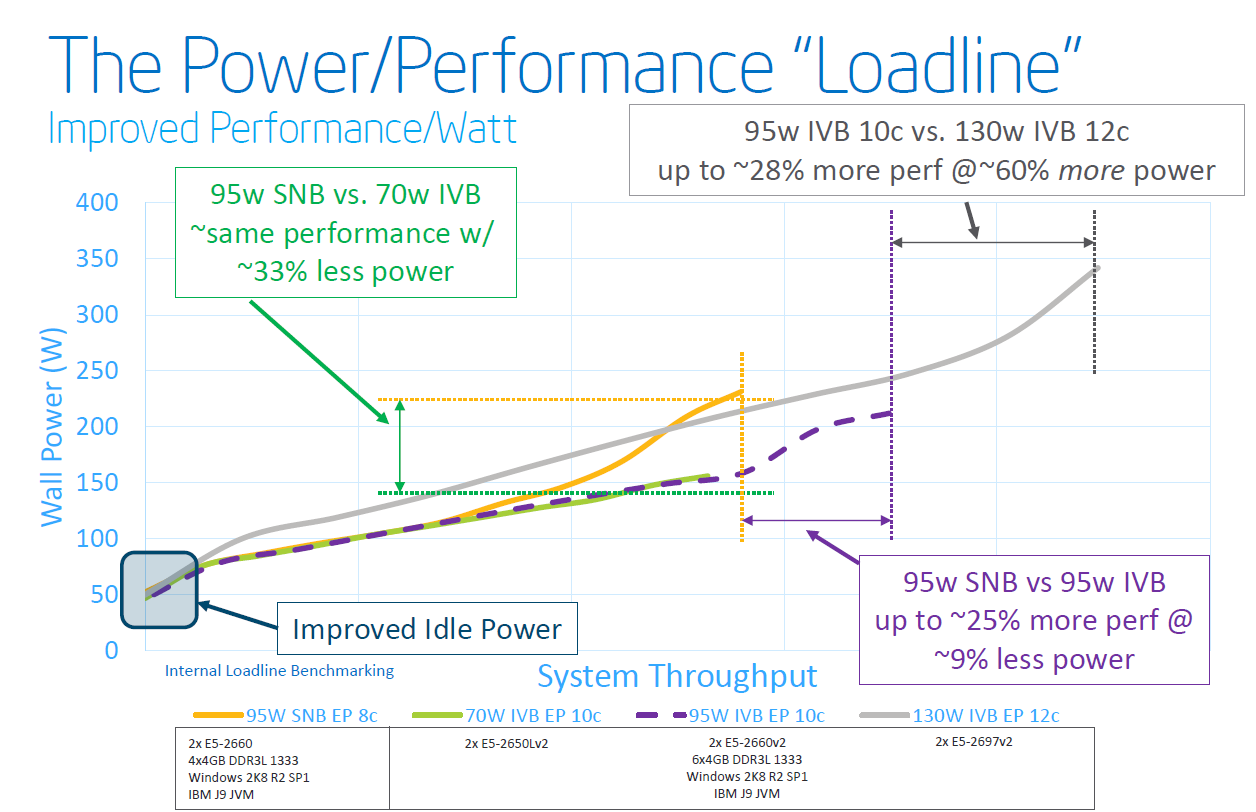
Focus on the purple text: within the same power envelope, the Ivy Bridge Xeon is capable of delivering 25% more performance while still consuming less power. In other words, the P1270 process allowed Intel to increase the number of cores and/or clock speed significantly. This can be easily demonstrated by looking at the high-end cores. An octal-core Xeon E5-2680 came with a TDP of 130W and ran at 2.7GHz. The E5-2697 runs at the same clock speed and has the same TDP label, but comes with four extra cores.
Virtualization Improvements
Each new generation of Xeon has reduced the amount of cycles required for a VMexit or a VMentry, but another way to reduce hardware virtualization overhead is to avoid VMexits all together. One of the major causes of VMexits (and thus also VMentries) are interrupts. With external interrupts, the guest OS has to check which interrupt has the priority and it does this by checking the APIC Task Priority Register (TPR). Intel already introduced an optimization for external interrupts in the Xeon 7400 series (back in 2008) with the Intel VT FlexPriority. By making sure a virtual copy of the APIC TPR exists, the guest OS is capable of reading out that register without a VMexit to the hypervisor.
The Ivy Bridge core is now capable of eliminating the VMexits due to "internal" interrupts, interrupts that originate from within the guest OS (for example inter-vCPU interrupts and timers). The virtual processor will then need to access the APIC registers, which will require a VMexit. Apparantly, the current Virtual Machine Monitors do not handle this very well, as they need somewhere between 2000 to 7000 cycles per exit, which is high compared to other exits.
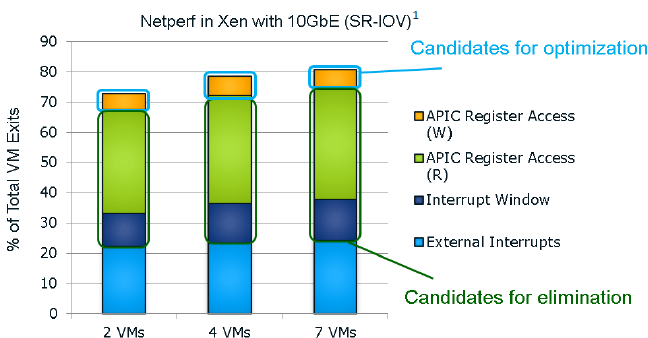
The solution is the Advanced Programmable Interrupt Controller virtualization (APICv). The new Xeon has microcode that can be read by the Guest OS without any VMexit, though writing still causes an exit. Some tests inside the Intel labs show up to 10% better performance.
Related to this, Sandy Bridge introduced support for large pages in VT-d (faster DMA for I/O, chipset translates virtual addresses to physical), but in fact still fractioned large pages into 4KB pages. Ivy Bridge fully supports large pages in VT-d.
Only Xen 4.3 (July 2013) and KVM 1.4 (Spring 2013) support these new features. Both VMware and Microsoft are working on it, but the latest documents about vSphere 5.5 do not mention anything about APICv. AMD is working on an alternative called Advanced Virtual Interrupt Controller (AVIC). We found AVIC inside the AMD64 programmer's manual at page 504, but it is not clear which Opterons will support it (Warsaw?).








70 Comments
View All Comments
Bytales - Tuesday, September 17, 2013 - link
Please make some gaming related tests. Im planning on upgrading from 2x2609 to 2x2690v2, now that i now for sure that 10 cores 25 mb cache is a complete die. I dont trust verz much the design on the 12 core die, its not how i would design the CPU. Besides the 2690v2 is 3ghz base and 3.6 boost, perfect for gaming.Would have like to see how a 2690v2 would compare with a 2687w v2 in gaming related tests, seeing as the latter has a 3.4 base 4 ghz boost but 2 cores less.
Anyways, im not pazing 3000+ euros on disabled die (like the one in 2687v2) so the 10 core is my choice, but still would have like to seee how higher freq lower core count would impact gaming performance !
mking21 - Wednesday, September 18, 2013 - link
I can tell you now that the 8 core is going to kick the 10 core's ass for gaming. The higher clock will win here. So as you are going to pay 3000 euros you may as well get the best, even if it does have two cores disabled. But I do agree for me a more interesting comparison would have been 12 vs 10 vs 8 all V2s all fastest clock available versions...mapesdhs - Wednesday, September 18, 2013 - link
IMO for gaming you'd be better off with a used oc'd 2700K. I just bought one for 160 UKP,
fitted with a used TRUE (cost 15), two new Coolermaster Blademaster fans, Q-fan active
(ASUS M4E mbd, used, cost 130), runs at 5GHz no problem, silent running when idle. See:
http://valid.canardpc.com/a64s8p
The vast majority of games gain the most from a sensible middle ground between
multiple cores and a high clock. Few will properly exploit more than 4 cores with HT.
Using a multi-core XEON for gaming is silly. You would see far greater gaming
performance by getting a much cheaper 4/6-core and spending the saved cash on
more powerful GPUs like two 780 or Titans SLI, or two 7970 CF, etc. A 4-core Z68
should be just fine, though if you do want oodles of PCIe lanes for high-end SLI/CF
then I'd get X79 and a 3930K (don't see the point of IB-E).
Trust me, a 5GHz 2700K, or a 4.7GHz 3930K, paired with two much better GPUs
via the saved money, will be massively better for gaming vs. what you could afford
having spent thousands on two 10 or 12-core CPUs with much lower clocks. Most
2600Ks will oc pretty nicely too.
Bytales, what GPU(s) do you have in your system atm?
Ian.
PS. IB/HW are a waste of time. They don't oc aswell as SB. I bought a 2500K for 125, only
took 3 mins to get it running 4.7 stable on a used Gigabyte Z68 board (which cost a mere 35).
Bytales - Saturday, September 21, 2013 - link
The reason im looking at xeons is because of the motherboard i own, which is the z9ped8ws, which i bought because i need the pci express lanes two xeons provide. No other motherboard could have gottwn me what this one does, and i have looked everywhere. Thats the reason i need these xeons. I originally bought two 2609 cpus and a crossfire tahiti le(one burned down due to bitcoin mining) their purpose were/are to make the pc usable until the new xeons and the new radeons wil become available. I know i wont be getting the best possible cpus for gaming on this platform. I just want some decent performers. The 2609 i have now are 2.4 ghz no boost no HT, and did their job good so far. Im expecting decent gaming performance out of a 3ghz chip with multiple cores. Sure, i could get the 2687wv2 for the same price, but i have a hate for disabled things. Why the hell didnt they make a 10 core chip with 25 mb cache 3.5 base 4ghz boost and 150 160 w tdp. I would have bought such a cpu. But as it is ill have to make due with two 2690. Maybe, just maybe, if i see some gaming benchmarks between the two cpus, i will consider the 2687wv2. Untill then, my first choice is the 2690.Hopefully, the people from anandtwch will test this aspect of the cpus, gaming that is, becauae all they tested was server/enterpriae stuff, which was to be expected after all.
Gaming was not what these cpus were built for. But i like having strong cpus which will have my back if i decie to do some other stuff as well. I do bunch of converting, compressing, autocad photoshop. Etc. Thats why more cores. The better.
Ktracho - Thursday, October 3, 2013 - link
I would think you can get the PCIe lanes you want with a motherboard that has a PLX bridge chip, such as the ASUS P9X79-E WS, without needing to resort to a two-socket motherboard. As far as gaming, I think the E5-1620 v2 gives good bang for the money, and if you need more cores, the E5-1650 v2 does well, too. If you need a little better performance, you can get the E5-1680 v2, but at a price. Too bad Intel doesn't sell single-socket CPU versions with more than 6 cores, though.MrSpadge - Tuesday, September 17, 2013 - link
The Xeon2660v2 could in theory be what Ivy-E should have been for enthusiasts: something at least a bit more worth spending big $ on. The mainboard would have to let us enable multi-core turbo and OC the bus though.psyq321 - Tuesday, September 17, 2013 - link
Situation with IvyBridge EP is absolutely the same as with Sandy Bridge EP:- No BCLK "straps" (or ratios) for Xeon line - only 100 MHz allowed
- No unlocked multipliers
- BCLK overclocking works - your mileage may vary. I can get up to 105 MHz with dual Xeon 2697 v2 setup on Z9PE D8 WS
So, Ivy Bridge EP Xeons do not overclock particularly well - the best you can get out of 2S parts (26xx v2) is 100-150 MHz depending on the max. turbo multiplier your SKU has.
ezekiel68 - Wednesday, September 18, 2013 - link
Johan, what do you mean by "...over four NUMA nodes" in the last sentence on the Compression And Decompression page?My understanding is that for both Opeteron and Xeon, a NUMA node is a complete CPU package (with all its cores) and the associated RAM directly connected to that CPU's memory controllers. In the charts, all of the Opterons are listed as "2x Opteron XXXX". Are you considering each die within the Opteron MCM package to be a separate NUMA node -- or how else are you coming up with "four" above?
JohanAnandtech - Friday, September 20, 2013 - link
AFAIK, the two dies in the package communicate via hypertransport links and it is quicker for one die to communicate with its own memory than with the memory attached to the second die.ddkeenan - Wednesday, September 18, 2013 - link
The data in this article is incomplete. The JVM tuning used is targeted for throughput alone, basically ignoring GC pause times. The critical jOPS metric is intended to measure with response time constraints, and the results posted here are most likely highly variable and definitely dreadfully low because of the poor tuning choices.Actual customers care more about response time/latency these days. Throughput is often solved by scaling horizontally, response time is not. Commercial benchmarking should try to reflect that desire by focusing on response time and the SPECjbb2013 critical jOPS in order to influence hardware and software vendors to compete.
Finally, to Kevin G, I think it's also likely that SPARC T-series systems have been focusing on customer metrics more than competitive benchmarks, and now there's a benchmark that takes response time into consideration.