AMD EPYC Milan Review Part 2: Testing 8 to 64 Cores in a Production Platform
by Andrei Frumusanu on June 25, 2021 9:30 AM ESTAMD Platform vs GIGABYTE: IO Power Overhead Gone
Starting off with the big change for toady’s review: the new production-grade GIGABYTE Milan compatible test platform.
In our original review of Milan, we had initially discovered that AMD’s newest generation chips had one large glass jaw: the platform’s extremely high idle package power behaviour exceeding 100W. This was a notable regression compared to what we saw on Rome, and we deemed it as a core cause as of why Milan was seeing some performance regressions in certain workloads compared to the predecessor Rome SKUs.
We had communicated our findings and worries to AMD prior to the review publishing, but never root-caused the issue, and never were able to confirm whether this was the intended behaviour of the new Milan chips or not. We theorized that it was a side-effect of the new sIOD which had the infinity fabric running at a higher frequency, which this generation runs in 1:1 mode with the memory controller clocks.
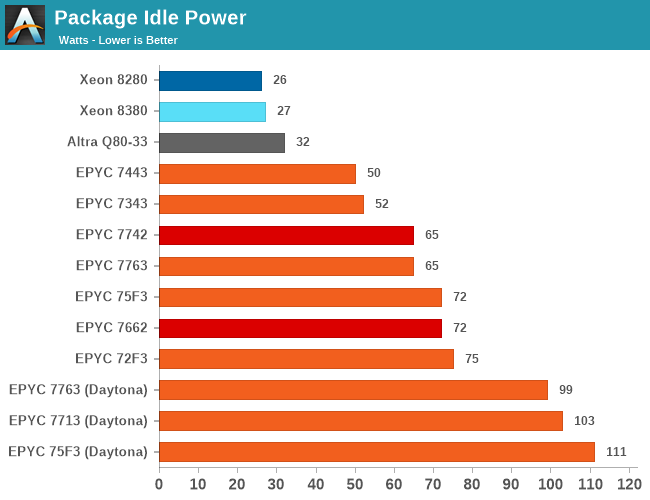
To our surprise, when setting up the new GIGABYTE system, we found out that this behaviour of extremely high idle power was not being exhibited on the new test platform.
Indeed, instead of the 100W idle figures as we had tested on the Daytona system, we’re now seeing figures that are pretty much in line with AMD’s Rome system, at around 65-72W. The biggest discrepancy was found in the 75F3 part, which now idles 39W less than on the Daytona system.
| Milan Power Efficiency | |||||||||||||
| SKU | EPYC 7763 (Milan) |
||||||||||||
| Motherboard/ Platform |
Daytona | GIGABYTE | |||||||||||
| TDP Setting | 280W |
||||||||||||
| Perf |
PKG (W) |
Core (W) |
Perf | PKG (W) |
Core (W) |
||||||||
| 500.perlbench_r | 281 | 274 | 166 | 317 | 282 | 195 | |||||||
| 502.gcc_r | 262 | 262 | 131 | 271 | 265 | 150 | |||||||
| 505.mcf_r | 155 | 252 | 115 | 158 | 252 | 132 | |||||||
| 520.omnetpp_r | 142 | 249 | 120 | 144 | 244 | 133 | |||||||
| 523.xalancbmk_r | 181 | 261 | 131 | 195 | 266 | 152 | |||||||
| 525.x264_r | 602 | 279 | 172 | 641 | 283 | 196 | |||||||
| 531.deepsjeng_r | 262 | 267 | 161 | 296 | 283 | 196 | |||||||
| 541.leela_r | 267 | 249 | 148 | 303 | 274 | 199 | |||||||
| 548.exchange2_r | 487 | 274 | 176 | 543 | 262 | 202 | |||||||
| 557.xz_r | 190 | 260 | 141 | 206 | 272 | 171 | |||||||
| SPECint2017 | 255 | 260 | 141 | 275 | 265 | 164 | |||||||
| kJ Total | 2029 | 1932 | |||||||||||
| Score / W | 0.980 | 1.037 | |||||||||||
| 503.bwaves_r | 354 | 226 | 90 | 362 | 218 | 99 | |||||||
| 507.cactuBSSN_r | 222 | 278 | 150 | 229 | 285 | 174 | |||||||
| 508.namd_r | 282 | 279 | 176 | 280 | 260 | 193 | |||||||
| 510.parest_r | 153 | 256 | 119 | 162 | 259 | 138 | |||||||
| 511.povray_r | 348 | 275 | 176 | 387 | 255 | 193 | |||||||
| 519.lbm_r | 39 | 219 | 84 | 40 | 210 | 92 | |||||||
| 526.blender_r | 372 | 276 | 165 | 396 | 282 | 188 | |||||||
| 527.cam4_r | 399 | 278 | 147 | 417 | 285 | 170 | |||||||
| 538.imagick_r | 446 | 278 | 178 | 471 | 268 | 200 | |||||||
| 544.nab_r | 259 | 278 | 175 | 275 | 282 | 198 | |||||||
| 549.fotonik3d_r | 110 | 220 | 86 | 113 | 215 | 95 | |||||||
| 554.roms_r | 88 | 243 | 106 | 89 | 241 | 119 | |||||||
| SPECfp2017 | 211 | 240 | 110 | 220 | 235 | 123 | |||||||
| kJ Total | 4980 | 4716 | |||||||||||
| Score / W | 0.879 | 0.9361 | |||||||||||
A more detailed power analysis of the EPYC 7763 during our SPEC2017 runs confirms the change in the power behaviour. Although the total average package power hasn’t changed much between the systems, in the integer suite now 5W higher at 265W vs 260W, and in the FP suite now 5W lower at 235W vs 240W, what more significantly changes is the core power allocation which is now much higher on the GIGABYTE system.
In core-bound workloads with little memory pressure, such as 541.leela_r, the core power of the EPYC 7763 went up from 148W to 199W, a +51W increase or +34%. Naturally because of this core power increase, there’s also a corresponding large performance increase of +13.3%.
The behaviour change doesn’t apply to every workload, memory-heavy workloads such as 519.lbm don’t see much of a change in power behaviour, and only showcase a small performance boost.
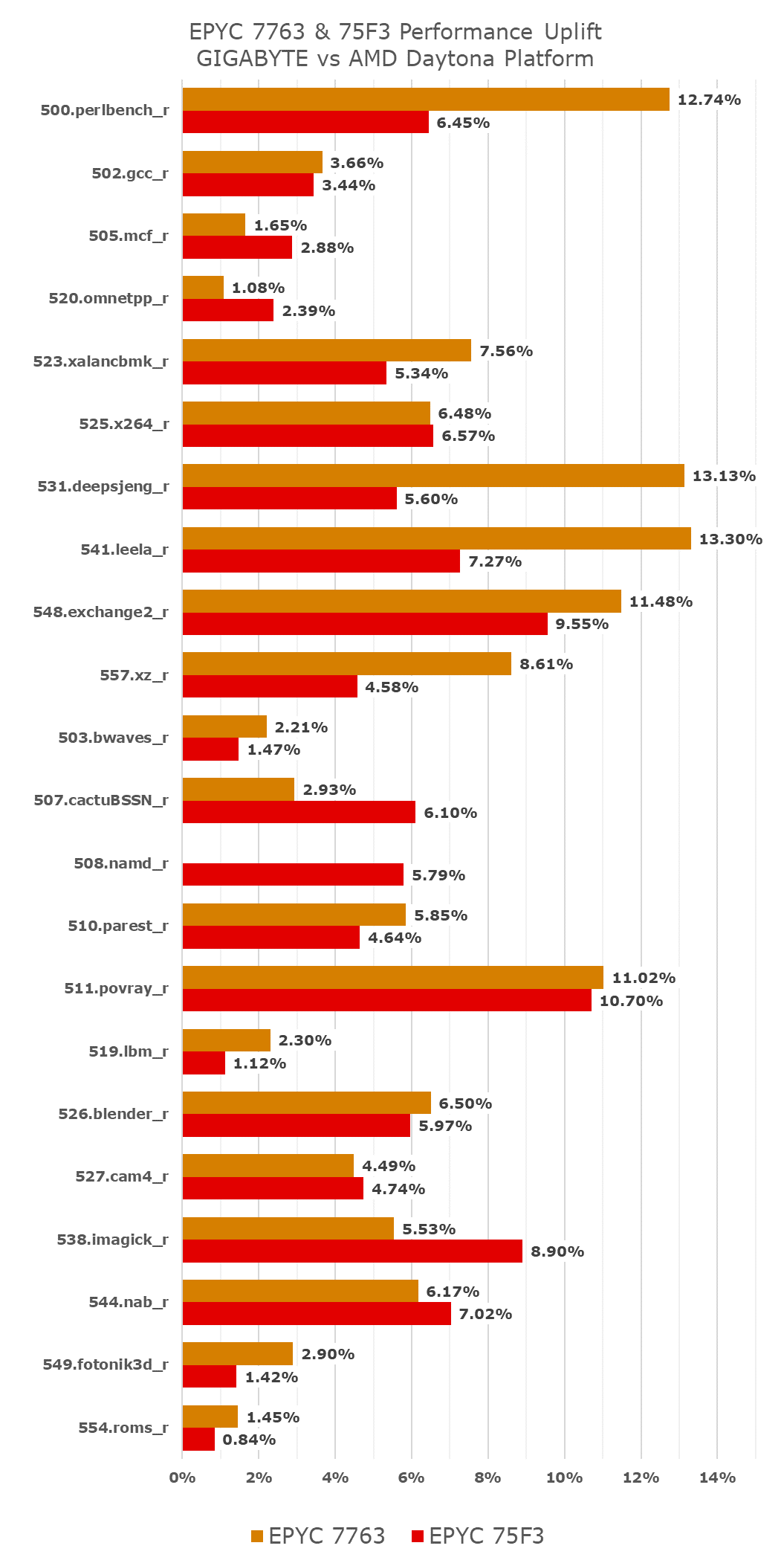
Reviewing the performance differences between the original Daytona system tested figures and the new GIGABYTE motherboard test-runs, we’re seeing some significant performance boosts across the board, with many 10-13% increases in compute bound and core-power bound workloads.
These figures are significant enough that they do change the overall verdict of those SKUs, and they also change the tone of our final review verdict on Milan, as evidently the one weakness the new generation had was actually not a design mishap, but actually was an issue with the Daytona system. It explains a lot of the more lacklustre performance increases of Milan vs Rome, and we’re happy that this was ultimately not an issue for production-grade platforms.
As a note, because we also have the 4-chiplet EPYC 7443 and EPYC 7343 SKUs in-house now, we also measured the platform idle power of those units, which came in at 50 and 52W. This is actually quite a bit below the 65-75W of the 8-chiplet 7763, 75F3 and 72F3 parts, which indicates that this power behaviour isn’t solely internal to the sIOD chiplet, but actually part of the sIOD and CCD interfaces, or as well the CCD L3 cache power.








58 Comments
View All Comments
mode_13h - Sunday, June 27, 2021 - link
Thanks for this update. Exciting findings!Gondalf - Sunday, June 27, 2021 - link
SPECint2017 is good but....SPECint2017 Rate to estimate the per-core performance, no no absolutely no. SPECint2017 Rate have a very small dataset and it can not be utilized to estimate the single core performance, we need of the full SPECint2017 workload, the only manner to bypass the crazy L3 of Ryzen. Half the article have a so so sense ( obviously SPEC Rate is very criticized by many and very likely means less than nothing, expeciallly if you rise the bar on L3 ), the other half nope, without sense.In fact Intel claim a new 10nm 32 cores superior than a 32 cores Milan, after all the two cores ( Zen 3 and Willow Cove) have around the same IPC, more or less, and being chiplets, 32 cores Milan is out of the games.
Obviously in this article the world "latency" is hidden or so. A single die solution is always better than chiplet design under load with the same number of cores.
Qasar - Sunday, June 27, 2021 - link
and there is the highly biased anti amd post from gondalf that he is known for." In fact Intel claim a new 10nm 32 cores superior than a 32 cores Milan, after all the two cores ( Zen 3 and Willow Cove) have around the same IPC, more or less, and being chiplets, 32 cores Milan is out of the games. "
yea ok, more pr bs from intel that you blindly believe ? post a link to this. the fact that you start with " in fact intel claim" kind of point to it being bs.
schujj07 - Monday, June 28, 2021 - link
Gandalf missed a link I posed that has a 32c Intel vs 32c AMD. In that the AMD averages 20% better performance than the Intel across the entire test suite. https://www.servethehome.com/intel-xeon-gold-6314u...iAPX - Sunday, June 27, 2021 - link
There's a lot to read and understand on the last chart (per-Thread score / Socket Perf), about usefulness of SMT (or not), about who is the per-Thread performance leader and also the per-Socket performance leader, with a notable exception, the Altra Q80-33.I would like to see these kind of chart more often, it sum-up things very clearly, while naturally you have to understand that it is just a long-story short, and have to read about specific performance depending on the payload (ie: DB as stated).
Kudos!
nordform - Thursday, July 1, 2021 - link
Too bad Apple's M1 was left out ... it clearly would have smoked the "competition". Everything with a TDP higher than 25W is inappropriate, not to say obscene.Apple rules hands down
Qasar - Friday, July 2, 2021 - link
" Everything with a TDP higher than 25W is inappropriate, not to say obscene. " and why would that be ?mode_13h - Friday, July 2, 2021 - link
That would be like drag racing a Tesla car against some 18-wheeled diesel trucks.Server CPUs are not optimized for low-thread performance. They're designed to scale, and have data fabrics to handle massive amounts of I/O that the M1 can't. It wouldn't be a fair (or relevant) comparison.
Now, try running that Tesla car in a tractor pull and we'll see who's laughing!
Oxford Guy - Thursday, July 8, 2021 - link
Happy to have won another debate in which my suggestion was aggressively attacked.I said having dual channel DDR4 for Zen 3 was unfortunate, as DDR4 is so long in the tooth — a fact that dual channel configuration makes more salient. I said it would have been good for the company to add more value by giving it quad channel RAM or, if possible, a support for both DDR4 and DDR5 — something some mainstream Intel quads had (support for DDR3 and DDR4).
My remark was derided mainly on the basis of the claim that dual channel is plenty. This new set of parts demonstrate the benefit of having more RAM and cache.
Considering how high the core counts are for Zen 3 desktop CPUs and how much Apple has set people on notice about what’s possible in CPU performance...
Also, part of the rebuttal was citing the existence of TR. That’s still Zen 2, eh? Can’t really go out and buy that rebuttal.
Is the benefit of being able to stay with the AM4 socket bigger than having less starvation of the CPU, particularly given the very high core counts of CPUs like the 5950? TR may be everyone’s segmentation dream (particularly when it’s being laughingly sold with obsolete Zen 2 and subjected to rapid expensive motherboard orphaning) but I think having five motherboard specs is a bridge too far. Let the low-end have dual channel and no overclocking, dump TR, and consolidate the enthusiast boards to a single (not two) chipset. But... that’s me. I like more value versus little crumbs and redundancies. When a whopping two companies is the state of the competition, though, people become trained to celebrate banality.
mode_13h - Thursday, July 8, 2021 - link
> Zen 3 was unfortunate, as DDR4 is so long in the tooth ...> it would have been good for the company to add more value by giving it quad channel RAM
Agreed. Would've been nice. In spite of that, the 5950X manages to show gains over the 5900X, but we can still wonder how much better it might be with more memory bandwidth.
I wouldn't have an issue with quad-channel being reserved for their TR platform if:
* they were more affordable
* they brought Zen3 to the platform more promptly
An interesting counter-point to consider is how little 8-channel RAM benefitted TR Pro:
"In the tests that matter, most noticeably the 3D rendering tests, we’re seeing a 3% speed-up on the Threadripper Pro compared to the regular Threadripper at the same memory frequency and sub-timings."
https://www.anandtech.com/show/16478/64-cores-of-r...
That's much less benefit than I'd have expected, as a 64-core TR on quad-channel should be far more bandwidth-starved than a 16-core Ryzen on dual-channel. However, that same article features a micro-benchmark which shows the full potential of 8-channel. So, it's obviously workload-dependent.