Futuremark Releases 3DMark Time Spy DirectX 12 Benchmark
by Daniel Williams on July 14, 2016 1:00 PM EST- Posted in
- GPUs
- Futuremark
- 3DMark
- Benchmarks
- DirectX 12

Today Futuremark is pulling the covers off of their new Time Spy benchmark, which is being released today for all Windows editions of 3DMark. A showcase of sorts of the last decade or so of 3DMark benchmarks, Time Spy is a modern DirectX 12 benchmark implementing a number of the API's important features. All of this comes together in a demanding test for those who think their GPU hasn’t earned its keep yet.
DirectX 12 support for game engines has been coming along for a few months now. To join in the fray Futuremark has written the Time Spy benchmark on top of a pure DirectX 12 engine. This brings features such as asynchronous compute, explicit multi-adapter, and of course multi-threading/multi-core work submission improvements. All of this comes together into what I think is not only visually interesting, but also borrows a large number of gaming assets from benchmarks of 3DMarks past.

For those who haven’t been following the 3DMark franchise for more than a decade, there are portions of the prior benchmarks showcased as shrunken museum exhibits. These exhibits come to life as the titular Time Spy wanders the hall, giving a throwback to past demos. I must admit a bit of fun was had watching to see what I recognized. I personally couldn’t spot anything older than 3DMark 2005, but I would be interested in hearing about anything I missed.
Unlike many of the benchmarks exhibited in this museum, the entirety of this benchmark takes place in the same environment. Fortunately, the large variety of eye candy present gives a varied backdrop for the tests presented. To add story in, we see a crystalline ivy entangled with the entire museum. In parts of the exhibit there are deceased in orange hazmat suits demonstrating signs of a previous struggle. Meanwhile, the Time Spy examines the museum with a handheld time portal. Through said portal she can view a bright and clean museum, and view bustling air traffic outside. I’ll not spoil the entire brief story here, but the benchmark makes good work of providing both eye candy for the newcomers and tributes for the enthusiasts that will spend ample time watching the events unroll.
From a technical perspective, this benchmark is, as you might imagine, designed to be the successor to Fire Strike. The system requirements are higher than ever, and while Fire Strike Ultra could run at 4K, 1440p is enough to bring even the latest cards to their knees with Time Spy.

Under the hood, the engine only makes use of FL 11_0 features, which means it can run on video cards as far back as GeForce GTX 680 and Radeon HD 7970. At the same time it doesn't use any of the features from the newer feature levels, so while it ensures a consistent test between all cards, it doesn't push the very newest graphics features such as conservative rasterization.
That said, Futuremark has definitely set out to make full use of FL 11_0. Futuremark has published an excellent technical guide for the benchmark, which should go live at the same time as this article, so I won't recap it verbatim. But in brief, everything from asynchronous compute to resource heaps get used. In the case of async compute, Futuremark is using it to overlap rendering passes, though they do note that "the asynchronous compute workload per frame varies between 10-20%." On the work submission front, they're making full use of multi-threaded command queue submission, noting that every logical core in a system is used to submit work.

Meanwhile on the multi-GPU front, Time Spy is also mGPU capable. Futuremark is essentially meeting the GPUs half-way here, using DX12 explicit multi-adapter's linked-node mode. Linked-node mode is designed for matching GPUs - so there isn't any Ashes-style wacky heterogeneous configurations supported here - trading off some of the fine-grained power of explicit multi-adapter for the simplicity of matching GPUs and useful features that can only be done with matching GPUs such as cross-node resource sharing. For their mGPU implementation Futuremark is using otherwise common AFR, which for a non-interactive demo should offer the best performance.
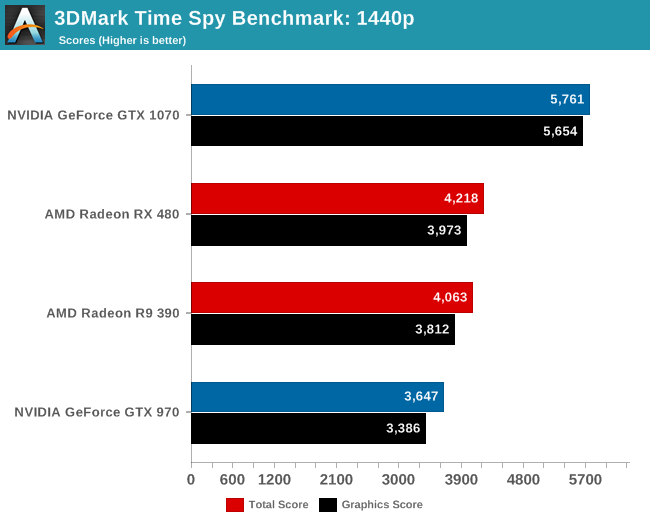
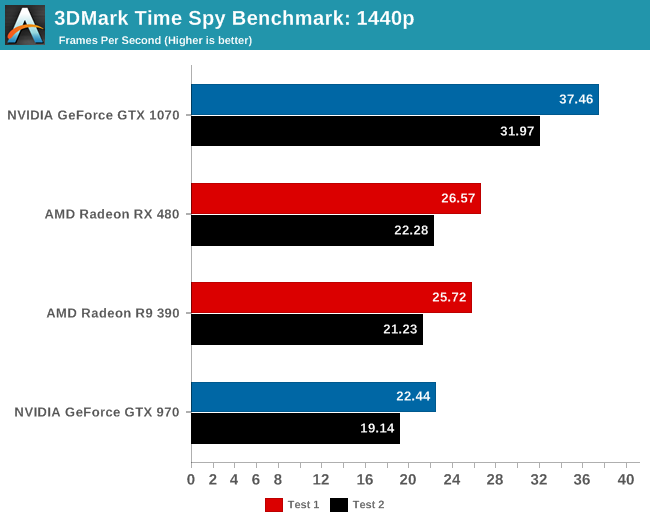
To take a quick look at the benchmark, we ran the full test on a small number of cards on the default 1440p setting. In our previous testing AMD’s RX 480 and R9 390 traded blows with each other and NVIDIA’s GTX 970. Here though, the RX 480 pulls a small lead over the R9 390 while they both leave a slightly larger gap ahead of the GTX 970. Only to then see the GeForce GTX 1070 appropriately zip past the lot of them.
The graphics tests scale similarly to the overall score in this case, and if these tests were a real game anything less than the GTX 1070 would provide a poor gameplay experience with framerates under 30 fps. While we didn’t get any 4K numbers off our test bench, I ran a GTX 1080 in my personal rig (i7-2600k @4.2GHz) and saw 4K scores that were about half of my 1440p scores. While this is a synthetic test, the graphical demands this benchmark can place on a system will provide a plenty hefty workload for any seeking it out.
Meanwhile, for the Advanced and Professional versions of the benchmark there's an interesting ability to run it with async compute disabled. Since this is one of the only pieces of software out right now that can use async on Pascal GPUs, I went ahead and quickly ran the graphics test on the GTX 1070 and RX 480. It's not an apples-to-apples comparison in that they have much different performance levels, but for now it's the best look we can take at async on Pascal.
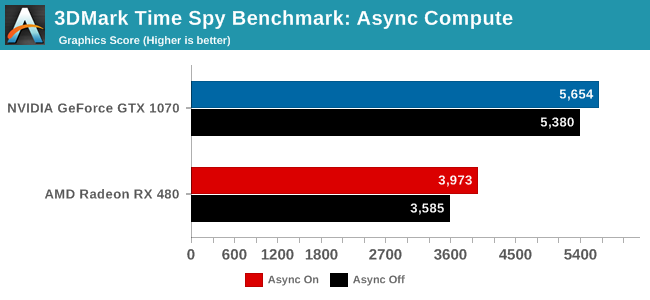
Both cards pick up 300-400 points in score. On a relative basis this is a 10.8% gain for the RX 480, and a 5.4% gain for the GTX 1070. Though whenever working with async, I should note that the primary performance benefit as implemented in Time Spy is via concurrency, so everything here is dependent on a game having additional work to submit and a GPU having execution bubbles to fill.
The new Time Spy test will be coming today to Windows users of 3DMark. This walk down memory lane not only puts demands on the latest gaming hardware but also provides another showcase of the benefits DX12 can bring to our games. To anyone who’s found FireStrike too easy of a benchmark, keep an eye out for Time Spy in the near future.








75 Comments
View All Comments
Scali - Saturday, July 16, 2016 - link
The 3DMark Technical Guide says as much: http://s3.amazonaws.com/download-aws.futuremark.co..."DirectX 11 offers multi-threaded (deferred) context support, but not all vendors implement it in hardware, so it is slow. And overall, it is quite limited."
bluesoul - Saturday, July 16, 2016 - link
Wow you must believe in yourself.Yojimbo - Thursday, July 14, 2016 - link
I don't think the static scheduling is done at a driver level. The way I understand it (and I am not a programmer, this is only from watching presentations) it is done at the request of the application programmer. And Pascal has a dynamic load balancing option which is able to override the requested balance, if allowed. I really don't know for sure, but I wonder if preemption might be used in their dynamic load balancing algorithm, but perhaps the one workload must completely finish before the other is rescheduled. I didn't see any details on how it works.Scali - Friday, July 15, 2016 - link
"but perhaps the one workload must completely finish before the other is rescheduled"That is what happens when there is no pre-emption. Pre-emption basically means that a workload can be stopped at some point, and its state saved to be continued at a later time. Another workload can then take over.
This is how multi-threading was implemented in OSes like UNIX and Windows 9x/NT, so multiple threads and programs can be run on a single core.
From what I understood about Maxwell v2's implementation, pre-emption was only possible between draw calls. So while the GPU can run various tasks in parallel, when you run a graphics task at the same time, you have to wait until it is finished before you can re-evaluate the compute tasks. As a result, compute tasks may have completed at some point during the draw call, and the compute units were sitting idle until they could receive new work.
This works fine, as long as your draw calls aren't taking too long, and your compute tasks aren't taking too little time. A common scenario is to have many relatively short draw calls, and relatively long-running compute tasks. In this scenario, Maxwell v2 will not lose that much time. But it implies that you must design your application workload in such a way, because if you don't, it may take a considerable hit, and it may be a better option not to try running many tasks concurrently, but rather running them one-by-one, each having the complete GPU at their disposal, rather than sharing the GPU resources between various tasks.
This is what you can also read here: https://developer.nvidia.com/dx12-dos-and-donts
With Pascal, pre-emption can occur at GPU instruction granularity, which means there is no longer any 'delay' until new compute tasks can be rescheduled. This means that units that would otherwise go idle can be supplied with a new workload immediately, and the efficiency of running concurrent compute tasks is not impacted much by the nature of the graphics work and overall application design.
Yojimbo - Friday, July 15, 2016 - link
I think that preemption (Why does everyone want to put a hyphen in the word? 'Emption' isn't even a word that I've heard of. Preemption, on the other hand, is.) and dynamic parallelism are two different things. The point of what I wrote that you quoted was that I haven't read anything which specifies how the dynamic parallelistic(?) algorithm works in Pascal. So I didn't want to assume that it relies on or even takes advantage of preemption.You seem to be saying that dynamic parallelism cannot be implemented without an improved preemption, but AMD seems to accomplish it. NVIDIA's hardware cannot schedule new work on unused SMs while other SMs are working without suspending those working SMs first? Is that what you're saying?
Scali - Friday, July 15, 2016 - link
Dynamic parallelism is yet another thing.Dynamic parallelism means that compute tasks can spawn new compute tasks themselves. This is not part of the DX12 spec afaik, and I don't know if AMD even supports that at all. It is a CUDA feature.
I was not talking about dynamic parallelism, but rather about 'static' parallelism, better known as concurrency.
Concurrency is possible, but the better granularity you have with pre-emption ('emption' is actually a word, as is 'pre', and 'pre-emption' is in the dictionary that way. It was originally a legal term), the more quickly you can switch between compute tasks and replace idle tasks with new ones.
And yes, as far as I understand it, Maxwell v2 cannot pre-empt graphics tasks. Which means that it cannot schedule new work on unused compute SMs until the graphics task goes idle (as far as I know this is excusively a graphics-specific thing, and when you run only compute-tasks, eg with CUDA HyperQ, this problem is not present).
In Pascal they removed this limitation.
Ryan Smith - Friday, July 15, 2016 - link
(We had a DB problem and we lost one post. I have however recovered the text, which is below)Sorry I said dynamic parallelism when I meant dynamic load balancing. Yes dynamic parallelism is as you say. But dynamic load balancing is a feature related to concurrency. What I meant to say: Preemption and dynamic load balancing are two different things. And it is not clear to me that preemption is necessary or if it is used at all in Pascal's dynamic load balancing. I am not sure if you know how it is done or not, but the reason I wrote what I did in my original message ("but perhaps the one workload must completely finish before the other is rescheduled") is because I didn't want to assume it was used.
As an aside, I believe when a graphics task is running concurrently with a compute task (within a single GPC? or within the GPU? Again, the context here is unclear to me), Pascal has pixel-level graphics and thread-level compute granularity for preemption, not instruction-level granularity. When only compute tasks are running (on the GPU or within a GPC??), Pascal has instruction-level preemption. Your previous message seem to imply that instruction-level granularity existed when running graphics a workload concurrently with compute tasks.
As far as emption, preemption, and pre-emption: https://goo.gl/PXKcmK
'Emption' follows 'pre-emption' so closely that one wonders how much 'emption' was ever used by itself since 1800. I do not believe you have seen 'emption' used very much. As for the dictionary, 'preemption' is definitely in the dictionary as the standard spelling. It seems clear the most common modern usage is 'preemption'. 'Pre-emption' is in no way wrong, I'm just wondering why people insist on the hyphen when 'emption' is hardly, if ever, used.
Scali - Saturday, July 16, 2016 - link
"I am not sure if you know how it is done or not, but the reason I wrote what I did in my original message ("but perhaps the one workload must completely finish before the other is rescheduled") is because I didn't want to assume it was used."But that is what pre-emption does, and we know that Maxwell and Pascal have pre-emption at some level.
"Pascal has pixel-level graphics and thread-level compute granularity for preemption, not instruction-level granularity."
What do you base this on?
nVidia has specifically stated that it has instruction-level granularity. See here:
https://images.nvidia.com/content/pdf/tesla/whitep...
"The new Pascal GP100 Compute Preemption feature allows compute tasks running on the GPU to be interrupted at instruction-level granularity, and their context swapped to GPU DRAM. This permits other applications to be swapped in and run, followed by the original task’s context being swapped back in to continue execution where it left off.
Compute Preemption solves the important problem of long-running or ill-behaved applications that can monopolize a system, causing the system to become unresponsive while it waits for the task to complete, possibly resulting in the task timing out and/or being killed by the OS or CUDA driver. Before Pascal, on systems where compute and display tasks were run on the same GPU, long-running compute kernels could cause the OS and other visual applications to become unresponsive and non-interactive until the kernel timed out."
So really, I don't know why so many people spread false information about nVidia's hardware.
bluesoul - Saturday, July 16, 2016 - link
in other words, or in laymen terms, does that mean that Maxwell v2 lacks the hardware or software required to gain from Async Compute?Scali - Saturday, July 16, 2016 - link
No, it means that Maxwell v2 is more sensitive to the mix of workloads that you want to run concurrently. So it's more difficult to gain from async compute, but not impossible.