The Apple Watch Review
by Joshua Ho & Brandon Chester on July 20, 2015 8:00 AM EST- Posted in
- Wearables
- Apple
- Mobile
- Apple Watch
Apple S1 Analysis
One of the biggest issues with the smartwatch trend that I’ve seen is that as a result of most companies entering the market with smartphone backgrounds, we tend to see a lot of OEMs trying to shove smartphone parts into a smartwatch form factor. There have been a lot of different Android Wear watches, but for the most part everything seems to use Qualcomm’s Snapdragon 400 without the modem. Even though A7 is relatively low power for a smartphone, it’s probably closer to the edge of what is acceptable in terms of TDP for a smartwatch. Given that pretty much every Android Wear watch has around a 400 mAh battery at a 3.8 or 3.85 volt chemistry to attempt to reach 1-2 days of battery life and a relatively large PCB, the end result is that these smartwatches are really just too big for a significant segment of the market. In order to make a smartwatch that can scale down to sizes small enough to cover most of the market, it’s necessary to make an SoC specifically targeted at the smartwatch form factor.

Capped Apple S1 SoC (Image Courtesy iFixit)
The real question here is what Apple has done. As alluded to in the introduction, it turns out the answer is quite a bit. However, this SoC is basically a complete mystery. There’s really not much in the way of proper benchmarking tools or anything that can be run on the Watch to dig deeper here. Based on teardowns, this SoC is fabricated on Samsung’s 28nm LP process, although it’s not clear which flavor of LP is used. It’s pretty easy to eliminate the high power processes, so it’s really just a toss-up between HKMG and poly SiON gate structure. For those that are unfamiliar with what these terms mean, the main difference that results from this choice is a difference in power efficiency, as an HKMG process has less leakage power. Given how little cost is involved in this difference in process compared to a move to 20/14nm processes, it’s probably a safe bet that Apple is using an HKMG process here especially when we look at how the move from 28LP to 28HPm at TSMC dramatically affected battery life in the case of SoCs like Snapdragon 600 and 800.

Decapped & Labeled S1 SoC (Image Courtesy ABI Research)
We also know that binaries compiled for the watch target ARMv7k. Unfortunately, this is effectively an undocumented ISA. We know that Watch OS is built on iOS/Darwin, so this means that a memory management unit (MMU) is necessary in order to make it possible to have memory protection and key abstractions like virtual memory. This rules out MCU ISAs like ARMv7m even if it's possible to add an MMU to such an architecture, so it’s likely that we’re looking at some derivative of ARMv7-A, possibly with some unnecessary instructions stripped out to try and improve power consumption.
The GPU isn’t nearly as much of a mystery here. Given that the PowerVR drivers present in the Apple Watch, it’s fairly conclusive that the S1 uses some kind of PowerVR Series 5 GPU. However which Series 5 GPU is up to debate. There are reasons to believe it may be a PowerVR SGX543MP1, however I suspect that it is in fact PowerVR's GX5300, a specialized wearables GPU from the same family as the SGX543 and would use a very similar driver. Most likely, dedicated competitive intelligence firms (e.g. Chipworks) know the answer, though it's admittedly also the kind of information we expect they would hold on to in order to sell it to clients as part of their day-to-day business activities.
In any case, given that native applications won’t arrive until WatchOS 2 is released I don’t think we’ll be able to really do much in the way of extensive digging on what’s going on here as I suspect that graphics benchmarks will be rare even with the launch of WatchOS 2.
Meanwhile, after a lot of work and even more research, we're finally able to start shining a light on the CPU architecture in this first iteration of Apple's latest device. One of the first things we can start to look at is the memory hierarchy, which is information crucial to applications that require optimization to ensure that code has enough spatial and/or temporal locality to ensure that code is performant.
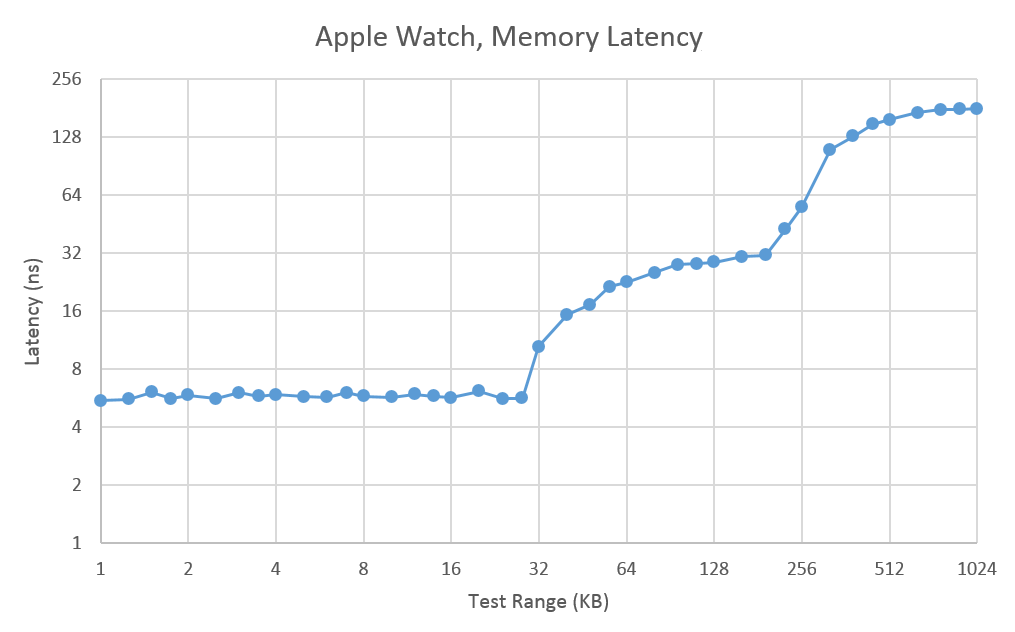
As one can see, there’s a pretty dramatic fall-off that happens between 28 and 64KB of “DRAM”, as we exit the local maximum of L1 data cache, so we can safely bet that the L1 data cache size is 32KB given current shipping products tend to fall somewhere between 32 and 64KB of L1 data cache. Given the dramatic fall-off that begins to happen around 224KB, we can also safely bet that we’re looking at a 256KB L2 combined cache which is fairly small compared to the 1-2MB shared cache that we might be used to from today’s large smartphone CPUs, but compared to something like an A5 or A7 it’s about right.
If Apple had just implemented the Cortex A7 as their CPU of choice, the obvious question at this point is whether they’ve really made anything “original” here. To try and dive deeper here, we can start looking past the memory hierarchy and looking closer at the machine itself. One of the first things that is obvious is that we’re looking at a CPU with a maximum frequency of 520 MHz, which is telling of the kind of maximum power that Apple is targeting here.
| Apple S1 CPU Latency and Throughput | ||||
| Instruction | Throughput (Cycles/Result) | Latency (Cycles/Result) | ||
| Loads (ldr reg,[reg]) | 1 | N/A | ||
| Stores (str reg,[reg]) | 1 | N/A | ||
| Move (mov reg, reg) | 1/2 | - | ||
| Integer Add (add reg, reg, imm8) | 1/2 | - | ||
| Integer Add (add reg,reg,reg) | 1 | 1 | ||
| Integer Multiply (mul reg,reg,reg) | 1 | 3 | ||
| Bitwise Shift (lsl reg,reg) | 1 | 2 | ||
| Float Add (vadd.f32 reg,reg,reg) | 1 | 4 | ||
| Double Add (vadd.f64 reg,reg,reg) | 1 | 4 | ||
| Float Multiply (vmul.f32 reg,reg,reg) | 1 | 4 | ||
| Double Multiply (vmul.f64 reg,reg,reg) | 4 | 7 | ||
| Double Divide (vdiv.f64 reg,reg,reg) | 29 | 32 | ||
Obviously, talking about the cache hierarchy isn’t enough, so let’s get into the actual architecture. On the integer side of things, integer add latency is a single cycle, but integer multiplication latency is three cycles. However, due to pipelining integer multiplication throughput can produce a result every clock cycle. Similarly, bitshifts take two cycles to complete, but the throughput can be once per clock. Attempting to interleave multiplies and adds results in only achieving half the throughput. We can guess that this is because the integer add block and the integer multiply block are the same block, but that doesn’t really make sense because of just how different addition and multiplication are at the logic level.
Integers are just half of the equation when it comes to data types. We may have Booleans, characters, strings, and varying bit sizes of integers, but when we need to represent decimal values we have to use floating point to enable a whole host of applications. In the case of low power CPUs like this one, floating point will also often be far slower than integers because the rules involved in doing floating point math is complex. At any rate, a float (32-bit) can be added with a throughput of one result per cycle, and a latency of four cycles. The same is true of adding a double or multiplying a float. However, multiplying or dividing doubles is definitely not a good idea here because peak throughput of multiplying doubles is one result per four clock cycles, with a latency of 7 clock cycles. Dividing doubles has a peak throughput of a result every 29 clock cycles, with a latency of 32 clock cycles.
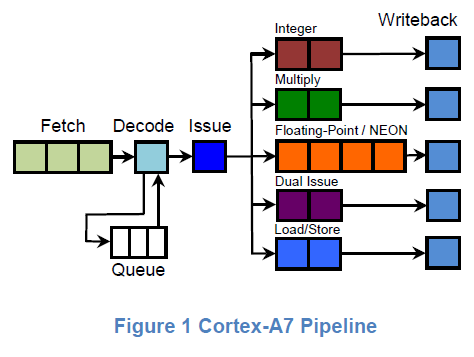
If you happen to have a webpage open with the latency and throughput timings for Cortex A7, you’d probably guess that this is a Cortex A7, and you’d probably be right as well. Attempting to do a load and a store together has a timing that indicates these are XOR operations which cannot be executed in a parallel manner. The same is true of multiplication and addition even though the two operations shouldn’t have any shared logic. Conveniently, the Cortex A7 has a two-wide pipeline that has similar limitations. Cortex A5 is purely single-issue, so despite some similarity it can't explain why addition with an immediate/constant value and a register can happen twice per clock.
Given the overwhelming amount of evidence at the timing level of all these instructions, it’s almost guaranteed that we’re looking at a single core Cortex A7 or a derivative of it at 520 MHz. Even if this is just a Cortex A7, targeting a far lower maximum clock speed means that logic design can prioritize power efficiency over performance. Standard cells can favor techniques and styles that would otherwise unacceptably compromise performance in a 2+ GHz chip could be easily used in a 520 MHz chip such as device stacking, sleepy stack layout, higher Vt selection with negative active body biasing, and other techniques that would allow for either lower voltage at the same frequency, or reduced capacitance in dynamic power and reduced static leakage. Given that Cortex A7 has generally been a winning design for perf/W metrics, I suspect that key points of differentiation will come from implementation rather than architecture for the near future. Although I was hoping to see Apple Watch on a more leading-edge process like 14LPP/16FF+, I suspect this will be deferred until Apple Watch 2 or 3.








270 Comments
View All Comments
supermoon7 - Monday, October 12, 2015 - link
You're so right! Use the watch for what it's intended for. It's not a computer. According to the guys at http://www.watchtimely.com it was originally meant to have a slightly larger screen to be able to do more complicated things, but the developers realized nobody would do them on their watch anyway.xihan94 - Friday, September 11, 2015 - link
+1 for the uncovered bonus chromosome 21.johnnycanadian - Monday, July 20, 2015 - link
... you seem to have a tremendous amount of time on your hands. Perhaps learning a new skill would be valuable?Schickenipple - Tuesday, July 21, 2015 - link
This guy has written book-length posts on pretty much every Apple product review. It's quite sad, really.I'd have to imagine that ANY skill other than ranting on and on about something he's never even used would go a long way... A career, maybe?
iWatchHogwash - Monday, July 20, 2015 - link
Dera BittenRottenApple,Excellent Analysis, what a great read, rationally and logically consistent, thank you very much.
By the way, some further recommendations to read and watch:
https://www.facebook.com/pages/I-hate-Apple/511277...
http://www.businessinsider.com/10-things-we-really...
https://www.youtube.com/watch?v=qa9d5mXc7eg&fe...
https://www.youtube.com/watch?v=90NJOpjq02M
http://www.fudzilla.com/news/wearables/38007-new-y...
http://www.nytimes.com/2015/04/09/technology/perso...
http://www.fudzilla.com/news/wearables/37610-lg-re...
Other Apple news not mentioned here:
Apple Watch sales fall by 90 per cent
Apple has another lemon
It is turning out exactly as we said – sales of Apple's latest cure for cancer have slumped to a shadow of their initial "glory."
While the Tame Apple Press and a big chunk of analysts sung praises for the iWatch, claiming it would sell 70 million in its first year. We pointed out that the gizmo was nearly two years out of date and lacked most of the software which would make it moderately useful and if it succeed it was a triumph of user stupidity and marketing.
Lately analysts have been slowly withdrawing the enthusiastic sales figures they gave the watch, and now a new survey has shown that sales have fallen by 90 per cent.
Apple is selling fewer than 20,000 watches a day in the US since the initial surge in April, and on some days fewer than 10,000. This is not too bad, but it does suggest that most people who wanted an iWatch have one, and existing users are not managing to win many converts amongst their friends to make it take off. For the record to make the 70 million figure apple would have to sell 195,000 a day.
Data collected by Slice Intelligence show that Two-thirds of the watches sold so far have been the lower-profit "Sport" version, whose price starts at $349, according to Slice, rather than the costlier and more advanced models that start at $549. Apple's gold "Edition" model priced at $10,000 or more has only sold 2,000 of them have been sold in the US.
The figures are based on the electronic receipts sent to millions of email addresses following purchases. The company conducts market research on behalf of consumer-goods companies, among others, many of them in the Fortune 500.
All up though these figures are not bad, but they are not the sort of numbers which Apple needs to convince its investors that it can make mega sales any more. With sales drying up in China, Jobs mob will not have a good bottom line this year.
Source:
http://www.fudzilla.com/news/wearables/38173-apple...
And
Apple puts iWatch in stores
Maybe some idiot will buy them
Apple mysteriously has enough iWatches on hand to start putting them in its own stores.
The iWatch went on sale six weeks ago and at the time Apple did not think it would ever have enough to put it in its own shops. The original plan was to flog them online and in fashion stores, however and Jobs' Mob thought it would never have enough to meet the crushing demand for an out-of-date wearable which was more expensive than anything else on the market.
So it appears that suddenly Apple has enough. Of course the Tame Apple Press is trying to keep the story about a shortage going. Potential buyers must first reserve their device online, and some models are still out of stock.
But the sport models, which are most popular and the cheapest, are available across the country, while others can be bought in Apple's flagship shops, such as those in London and Manchester.
In order to reserve your device, you must pick the Watch you want to buy, choose a store to pick the device up and then choose a time to go and buy it.
You can also order the home delivery, but it's not recommended as it takes more than three weeks for the shipment to be delivered.
The most expensive models, such as the 38mm yellow gold model with red modern Buckle strap, are still unavailable. As Apple said last week, the 42mm Watch in Space Black with the metal link bracelet is unavailable at all stores for now.
Source:
http://www.fudzilla.com/news/wearables/38018-apple...
Finally some related news (pasted in chronological order from new to old):
http://www.fudzilla.com/news/38274-apple-press-gea...
http://www.fudzilla.com/news/wearables/38254-apple...
http://www.fudzilla.com/news/wearables/38173-apple...
http://www.fudzilla.com/news/wearables/38126-analy...
http://www.fudzilla.com/news/wearables/38018-apple...
http://www.fudzilla.com/news/38017-apple-is-convic...
http://www.fudzilla.com/news/wearables/38007-new-y...
http://www.nytimes.com/2015/04/09/technology/perso...
http://www.fudzilla.com/news/38004-xiaomi-sells-6-...
http://www.fudzilla.com/news/37983-twitter-thinks-...
http://www.fudzilla.com/news/wearables/37893-zenwa...
http://www.fudzilla.com/news/wearables/37889-apple...
http://www.fudzilla.com/news/37832-analyst-realise...
http://www.fudzilla.com/news/37787-quanta-clarifie...
http://www.fudzilla.com/news/wearables/37756-apple...
http://www.fudzilla.com/news/wearables/37660-iwatc...
http://www.fudzilla.com/news/wearables/37646-apple...
http://www.fudzilla.com/news/37635-apple-results-s...
http://www.fudzilla.com/news/wearables/37610-lg-re...
http://www.fudzilla.com/news/37609-is-the-iphone-a...
http://www.fudzilla.com/news/wearables/37586-apple...
http://www.fudzilla.com/news/wearables/37558-apple...
http://www.fudzilla.com/news/37499-imac-is-getting...
http://www.fudzilla.com/news/wearables/37485-apple...
http://www.fudzilla.com/news/wearables/37391-apple...
http://www.fudzilla.com/news/wearables/37350-apple...
http://www.fudzilla.com/news/37349-apple-a-trillia...
http://www.fudzilla.com/news/mobile/37278-new-ios-...
http://www.fudzilla.com/news/37248-apple-blames-se...
http://www.fudzilla.com/news/wearables/37235-devel...
http://www.fudzilla.com/news/mobile/37224-iphone-i...
http://www.fudzilla.com/news/wearables/37130-mobil...
http://www.fudzilla.com/news/wearables/37048-apple...
http://www.fudzilla.com/news/wearables/37001-study...
http://www.fudzilla.com/news/wearables/36699-apple...
http://www.fudzilla.com/news/wearables/36603-consu...
http://www.fudzilla.com/news/wearables/36427-sony-...
http://www.fudzilla.com/news/36342-intel-outclasse...
http://www.fudzilla.com/news/mobile/36183-microsof...
http://www.fudzilla.com/news/mobile/36169-microsof...
http://www.fudzilla.com/news/36080-microsoft-beats...
http://www.fudzilla.com/news/mobile/35959-apple-wa...
http://www.fudzilla.com/news/35740-doctors-rubbish...
http://www.fudzilla.com/news/mobile/35694-rumour-i...
Have a nice day.
Ryan Smith - Monday, July 20, 2015 - link
In the interest of transparency, BittenRottenApple has been banned from AnandTech. We have since identified him as a sockpuppet having used multiple accounts here, and while we afford our readers a great deal of liberty to discuss products and articles, we will not put up with people who are dishonest in their actions.Dennis Travis - Wednesday, July 22, 2015 - link
Ryan, thank you. It's for the good of the site. I was about to reply to him but glad I read this first!Again thanks for getting rid of people like that. Just brings the whole comments section down.
colonelclaw - Wednesday, July 22, 2015 - link
Thanks for that Ryan, on the internet it's easy to say "you need to get some kind of help" in jest, but in this case I think it may actually be true. Presumably iWatchHogwash is the same person?sammery - Tuesday, July 21, 2015 - link
Goodness me. That was so long and devoid of meaning I might start using it instead of Lorem Ipsum.WinterCharm - Tuesday, July 21, 2015 - link
Take your neurotic apple hating bullshit elsewhere.You're just bitter that Anandtech gave the watch a stellar review.