Smarter Prefetching and Caching
Making sure that the right instructions and data are ready for use in the caches in the "3 GHz and beyond" era is one of the most important tasks of the architectural engineer. This helps to ensure performance increases as clockspeeds get pushed higher; otherwise, higher CPU clockspeeds will simply result in the processor spending more time waiting for data. This technique of priming the caches is knows as Prefetching; however, the current hardware prefetching algorithms don't always lead to success. There are quite a few cases where they can actually lower performance, especially in bandwidth sensitive applications.The Core architecture prefetching is without any doubt superior to what can be found in the Athlon 64 and Pentium 4. There are no less than three prefetchers - two data, one instruction - in each core, plus two prefetchers for the L2-cache. With eight prefetchers active in one dual-core Core CPU, all those prefetchers could easily get in the way of the "demand" bandwidth - the bandwidth which is needed by the load operations of the running program. In order to avoid this bottleneck, the prefetch monitor of the Core CPUs always give priority to the demand bandwidth; the prefetchers will never steal too much bandwidth away from the running program.
There is more. The data prefetch needs to perform tag lookups (tags = index of cache) in the caches frequently. To avoid this resulting in higher latency for the "normal" (caused by the program running) tag lookups, the data prefetch uses the store port for the tag lookup. If you remember, loads happen about twice as often as stores. This means the store port is used only half as much as the load port and it make sense to use that port for tag lookup by the prefetchers. Note also that stores are not critical for system performance in most cases -- once the data is "written" the processor can go on about its business. The cache/memory subsystem is in charge of replicating the data down to main memory, and as long as this happens eventually, everything works fine.
The cache system of the Core CPU is also very impressive. A massive 4 MB L2-cache is shared between the two cores and is accessed in only 12 to 14 cycles. Each core also has a 3 cycle 32 KB Instruction cache and a 32 KB data cache at its disposal. Note that the "Trace Cache" of NetBurst has been left behind with the return to shorter pipelines; the NetBurst Trace Cache basically functions as an instruction cache for pre-decoded instructions, and while this was apparently helpful for the long pipeline of NetBurst, Intel has apparently determined that a traditional L1 caching scheme makes more sense for Core.
Cache Architecture Overview
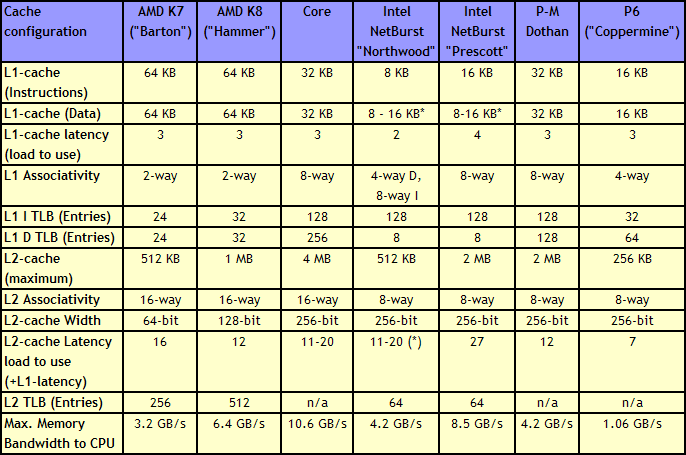 |
| Click to enlarge |
Just a quick look at the numbers in the above table make it clear that the memory subsystem of the Core architecture is impressive. It has twice as much L2 cache as current dual-core CPUs (the same amount as Presler), but the cache is still accessible with low latency. The shared L2 cache also allows one core to use more than 2MB of cache if necessary. Both L1 and L2 cache are accessed via a 256-bit wide bus, allowing the caches to deliver massive bandwidth to the core.
Core versus Hammer: Memory subsystem
Core's most important competitor, the Hammer ("K8") architecture, has two small but noteworthy advantages. The first is its bigger 2 x 64 KB L1 cache. This is only a small advantage as an 8-way 32 KB cache will have a hit rate close to that of a 2-way 64 KB cache.The second and more important advantage is the on die memory controller, which lowers the latency to the memory considerably. However, the lower clockspeeds of the Core CPUs (relative to NetBurst) and the faster FSB also lower latency significantly. With the numbers available to us now, we have reason to believe that the Athlon 64 X2's latency advantage will shrink to only 15 to 20%. For comparison, the memory subsystem of the Pentium 4 was almost twice as slow as the Athlon 64 (80-90 ns versus 45-50 ns).
However, those two small advantages are likely negated by all the other memory subsystem metrics. The Core CPUs have much bigger caches and much smarter prefetching than the competition. The Core architecture's L1 cache delivers about twice as much bandwidth (Measured by ScienceMark), while it's L2-cache is about 2.5 times faster than the Athlon 64/Opteron one.








87 Comments
View All Comments
Betwon - Wednesday, May 3, 2006 - link
Without branch prediction, K8 will become very very poor. Too terrible!The prediction is much better than the forever penalty.
The penalty of disprediction is just the penalty of doing nothing.(don't predict)
The penalty is fairly high. If you are against the prediction, you will find that the penalty will happen in K8 every 3 instructions averagely. K8@1.8G(without branch predictor ) will fail to win the old Pentium3@1G(with branch predictor ).
This is the drawback of lack of prediction, whether branches or memory access: It can not speeds up anything, but often slows down.
Without branch prediction, K8 will be down!
Betwon - Wednesday, May 3, 2006 - link
It is very interesting that the P4's Load/store/Memory reordering method, which is very different with Core's.For P4, it always assumes that all load-ops can hit and find the load data from the store buffer or L1 data cache.
Before one load-op is executed, it has to obtain the load address and all prior-store address and compare with them. If it is found that the load address is equal to one prior-store address, the load-op will assume that the store data is in the store buffer and the data has been ready and vaild, then start to execute speculatively.
If the address-euqal is not found, the load-op will assume that the load data is in L1 data cache, and the data is ready and vaild, then start to execute speculatively.
If the speculation fail or the miss happen, the speculative load-op and the relative speculative micro-ops have to be reexecuted -- it is called as 'replay'.
The load-op can be executed speculatively, after it knew it's load address and compared the load address with the all prior-store address.
The load-op can not be executed speculatively before it knew it's load address and compared the load address with the all prior-store address.
The load-op speculates whether the load data is ready and vaild, but not speculate whether there is the true dependency with prior-store.
But Core can speculate whether there is the true dependency with prior-store. Core has the smart predictor which can predict the store-to-load dependency precisely, before the load-op address is compared with the prior-store address.
Betwon - Wednesday, May 3, 2006 - link
If you really want to know what is the Intel's load reordering and memory misambiguation, I can tell you the facts:http://www.stanford.edu/~merez/papers/LoadSched_IS...">http://www.stanford.edu/~merez/papers/LoadSched_IS...
Speculation Techniques for Improving Load Related Instruction Scheduling 1999
Adi Yoaz, Mattan Erez, Ronny Ronen, and Stephan Jourdan -- From Intel's Haifa, they designed the Load/Store Unit of Core.
I had said that anandtech should study many things about CPU. Of course, I should study more things about CPU.
Betwon - Wednesday, May 3, 2006 - link
sub ebp,ebpmov ecx, 1000000000
B1:
mov eax,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov edx,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov eax,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov edx,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov eax,[ebx]
sub esi,1
sub edi,1
cmp ecx,ebp
je B2
mov edx,[ebx]
sub ecx,1
sub edi,1
cmp ebp,ebp
je B1
B2:
If the asm codes take 6000000000 cycles --> up to five x86 instructions at a time.
It is so easy to verify.
we can not call K5 -- 4 decoders, because it is too immature.
emboss - Monday, May 1, 2006 - link
I'm not even sure the Core architecture has 4 decoders. There's lots of references in the Intel Optimisation manual to say that there's still only three (two simple + one complex):"On Intel Core Solo and Intel Core Duo processors, decoding of most packed SSE instructions is done by all three decoders. As a result the front end can process up to three packed SSE instructions every cycle." (page 1-32)
"Improvement in decoder and micro-op fusion allows the front end to see most instructions as single µop instructions. This increases the throughput of the three decoders in the front end." (page 1-31)
While it certainly wouldn't be the first time Intel manuals have been wrong, they're usually reasonably accurate.
Also from the optimisation manual, it implies that the front end/decoder doing the fusion (for example, see the second quote above).
JarredWalton - Monday, May 1, 2006 - link
Not sure if you're referring to Core Solo/Duo manuals or to Core "Conroe/Merom" manuals. The article is covering the *next* Core architecture, so I wouldn't be at all surprised if Core Duo only has 3 decoders while Conroe bumps that to 4.emboss - Monday, May 1, 2006 - link
Oops, yes, my mistake. I was referring to Solo/Duo. Damn those marketers :)This still leaves me puzzled over the unexpected SSE performance on Solo/Duo. Thinking about it a bit more, the performance would have been 4x "expected" (single uop SSE with two FADD units vs double uop SSE with only one FADD unit), whereas I was only getting a bit less than double. Gnah, back to emperical optimisation.
Furen - Monday, May 1, 2006 - link
Yes, Yonah only has 3 decoders (and the same port arrangement as Dothan, too).Loki726 - Monday, May 1, 2006 - link
Great job Johan!Its articles like this that keep anandtech head and shoulders above everyone else. Instead of just running the latest and greatest core you get through the same old benchmarks and throwing some pretty comparison graphs at the reader, you actually take the time to figure out what parts of the architecture contribute to the performance you see in benchmarks. Keep it up!
On a small side note, on your first figure of intel's core architecture on page 4, I think the cache size should be 4096kb. 4gb seems rather large...
Goi - Monday, May 1, 2006 - link
Nice read. Did you get all your information solely from Jack Doweck, or are there papers outlining the Core architecture. I've read those for the Pentium-M and Netburst architecture(as well as several other architectures) but I haven't seen one of the Core yet.