Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
The limits of TLP...
Hardware engineers do not believe in massive superscalar CPUs anymore[2]. Increasing ILP a tiny bit requires exponentially bigger out-of-order hardware, which exponentially requires more power.
TLP and multi-core is hot and trendy. But the same problems that were true for squeezing ILP out of hardware are true about TLP in software. On the exception of naturally parallel applications such as rendering and database servers, getting more and more threads out of the majority of hardware will require exponentially more programming and debugging time. There are more high TLP designs such as Sun's Niagara that increase throughput, but also response time. And while the numbers of users that can update and read the database matters, the response time of the database can be important too. For example, while OLTP loads consist of many relatively simple SQL selects, Decision Support Systems (DSS or OLAP) fire off very complex queries with a high response time. To offer a good "data mining" experience, the single thread performance must not be neglected. The same can be said for some HPC and many typical workstation applications.
So, while designs that sacrifice ILP completely on the altar of TLP, such as Sun's Niagara, they may well be very popular in some markets such as webserving. Single thread performance is going to make the difference between the different multi-core solutions.
Here, the Itanium can leverage two big advantages: higher ILP and smaller cores. This last comment might seem ridiculous, given that the current Itanium Madison is about 432 mm2 large. However, if we look at the core (L1 inclusive), there about 25 million transistors that take about 80 mm2 die space. Note that the pictures below have been scaled and resized to reflect the relative proportions of the different cores.
Itanium: a slim figure
We compare the different CPU cores in the table below. We consider the L1-cache being part of the core, but we list the number of transistors separately to be clear. To keep it fair, we compare all CPU using the same process technologies, 0.13µ, with the exception of the Intel Xeon.
There is no doubt that a 0.13µ Xeon MP is no match for either of the IBM Power 5, the Itanium or Opteron with both Spec FP2000 and SpecInt around 1200 for a Xeon MP 3 GHz. The Xeon MP 0.13µ is also a 32 bit CPU, so it does not belong in the list below.
The reason why I listed the 90nm Xeon (DP) is to show how complex an x86 architecture can get when it has 64 bit and an extremely deep pipeline in a quest for high clock speeds, which must negate the low ILP. With more than 50 million transistors, it is no wonder that Xeon "Irwindale/Nocona" is the hottest CPU (per core) of the bunch despite being manufactured in a more advanced process.
Why do we use Spec FP2000 and Spec Int2000[3]? It is true that these benchmarks are close to meaningless when you want to compare server or workstation performance in the real world. Spec FP is a decent predictor of HPC/scientific performance, but fails to predict Digital Content Creation performance despite containing a few OpenGL benchmarks. The reason why we use these two benchmarks is that currently, we are evaluating the CPU architecture, its future potential and current compiler performance, and not the complete system.
* per core, two cores: about 70 million transistors
** for two cores
To calculate the cache sizes, we used the following formula:
HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 million transistors, which still includes the x86 compatibility transistors (about 4 million) and the L2-tag. It wouldn't be fair to include the x86 transistors when we compare the merits of EPIC with x86 and RISC.
And, what about the Pentium M? Well, the core is about 25 million transistors, but it is pretty hard to compare this CPU with Itanium as the Pentium M is optimised for low power consumption. If we keep it fair and compare the two cores using the same process technology, the Pentium M isn't even close when it comes to performance. A 2 GHz Pentium M scores a respectable 1500 in SpecInt, but trails far behind with a specfp score of about 1000.
Hardware engineers do not believe in massive superscalar CPUs anymore[2]. Increasing ILP a tiny bit requires exponentially bigger out-of-order hardware, which exponentially requires more power.
TLP and multi-core is hot and trendy. But the same problems that were true for squeezing ILP out of hardware are true about TLP in software. On the exception of naturally parallel applications such as rendering and database servers, getting more and more threads out of the majority of hardware will require exponentially more programming and debugging time. There are more high TLP designs such as Sun's Niagara that increase throughput, but also response time. And while the numbers of users that can update and read the database matters, the response time of the database can be important too. For example, while OLTP loads consist of many relatively simple SQL selects, Decision Support Systems (DSS or OLAP) fire off very complex queries with a high response time. To offer a good "data mining" experience, the single thread performance must not be neglected. The same can be said for some HPC and many typical workstation applications.
So, while designs that sacrifice ILP completely on the altar of TLP, such as Sun's Niagara, they may well be very popular in some markets such as webserving. Single thread performance is going to make the difference between the different multi-core solutions.
Here, the Itanium can leverage two big advantages: higher ILP and smaller cores. This last comment might seem ridiculous, given that the current Itanium Madison is about 432 mm2 large. However, if we look at the core (L1 inclusive), there about 25 million transistors that take about 80 mm2 die space. Note that the pictures below have been scaled and resized to reflect the relative proportions of the different cores.
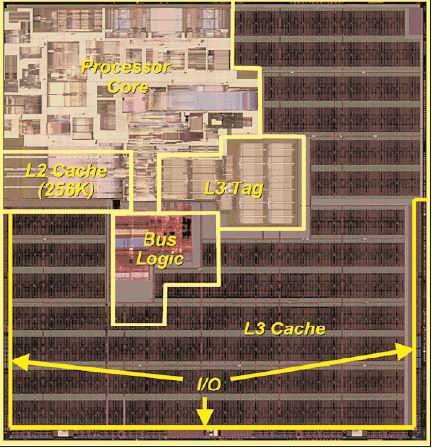
Madison 9 MB die
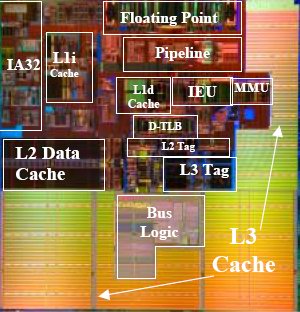
Madison core parts

Opteron die, rotated 90°
Itanium: a slim figure
We compare the different CPU cores in the table below. We consider the L1-cache being part of the core, but we list the number of transistors separately to be clear. To keep it fair, we compare all CPU using the same process technologies, 0.13µ, with the exception of the Intel Xeon.
There is no doubt that a 0.13µ Xeon MP is no match for either of the IBM Power 5, the Itanium or Opteron with both Spec FP2000 and SpecInt around 1200 for a Xeon MP 3 GHz. The Xeon MP 0.13µ is also a 32 bit CPU, so it does not belong in the list below.
The reason why I listed the 90nm Xeon (DP) is to show how complex an x86 architecture can get when it has 64 bit and an extremely deep pipeline in a quest for high clock speeds, which must negate the low ILP. With more than 50 million transistors, it is no wonder that Xeon "Irwindale/Nocona" is the hottest CPU (per core) of the bunch despite being manufactured in a more advanced process.
Why do we use Spec FP2000 and Spec Int2000[3]? It is true that these benchmarks are close to meaningless when you want to compare server or workstation performance in the real world. Spec FP is a decent predictor of HPC/scientific performance, but fails to predict Digital Content Creation performance despite containing a few OpenGL benchmarks. The reason why we use these two benchmarks is that currently, we are evaluating the CPU architecture, its future potential and current compiler performance, and not the complete system.
| CPU feature | Intel Itanium "Madison" | Intel Xeon P4 Irwindale | IBM Power 5 (+) | AMD Opteron |
| Process technology | 0.13 µ CU | 0.09 µ CU | 0.13 µ CU SOI | 0.13 µ CU SOI |
| Die Size (mm2) | 432 | 130 | 389 | 190 |
| Number of transistors (Million) | 592 | 169 | 276 | 106 |
| Number of transistors (Million) L1-cache | 1.8 | +/- 6 | 5.3 | 7.7 |
| Number of transistors (Million) L2 Cache | 14 | 113 | 107 | 57 |
| Number of transistors (Million) L3 Cache | 510 | 0 | off die | 0 |
| Number of transistors (Million) Tag (L2 + L3) | 23 | 4 | 33 | 4 |
| Number of transistors (Million) Core | 20 | 50 | 35* | 40 |
| Pure logic core (-L1) | 18 | 44 | 30 | 32 |
| Top clock speed | 1600 | 3800 | 1900 | 2600 |
| Best Spec FP2000 Score | 2712 | 1898 | 2839 | 1955 |
| Best Spec Int2000 Score | 1590 | 1810 | 1470 | 1713 |
| TDP | 107 W | 115-130 W | 200 W** | <95W |
** for two cores
To calculate the cache sizes, we used the following formula:
Cache size expressed in Bytes x 9 bits per byte (8 + 1 bit ECC/parity protection) x 6 Transistors per bit (SRAM)We calculated the Power 5 core as follows. The PowerPC 970FX, aka Apple's G5, is essentially a Power 4 core with Altivec, but without the L3 cache tag. If we subtract the number of transistors of the L2 cache (28 million) from the total number of transistors in the PowerPC 970, we end up with about 30 million transistors. The Power 5 core is a bit more complex (SMT and a few tweaks have been added), so we estimate it at about 35 million transistors.
HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 million transistors, which still includes the x86 compatibility transistors (about 4 million) and the L2-tag. It wouldn't be fair to include the x86 transistors when we compare the merits of EPIC with x86 and RISC.

The Itanium core is twice as small as the Xeon's
And, what about the Pentium M? Well, the core is about 25 million transistors, but it is pretty hard to compare this CPU with Itanium as the Pentium M is optimised for low power consumption. If we keep it fair and compare the two cores using the same process technology, the Pentium M isn't even close when it comes to performance. A 2 GHz Pentium M scores a respectable 1500 in SpecInt, but trails far behind with a specfp score of about 1000.








43 Comments
View All Comments
Starglider - Wednesday, November 9, 2005 - link
Well, back in university I passed my classes on CPU design, and I know a couple of flaours of assembly language and have worked on compilers professionally, so yes I'd say I know what I'm talking about.Hell, why am I being polite, /of course/ you can combine static and dynamic optimisation of instruction order. All x86 compilers /already/ do this. Virtual machine based programming languages (e.g. C# and Java) actually have /three/ tiers of optimisation; the primary compiler optimises the bytecode based on static global information, the runtime compiler optimises for the target instruction set based on medium-scale runtime information (at least Sun's Hotspot does), and then the CPU does instruction reordering and register remapping based on very local information. The efficiency of the final stage, e.g. the processor-level scheduling, can be improved by embedding hints in the instruction stream in exactly the same way that JIT compliation cane be improved by embedding hints in the bytecode of a VM language. Indeed arguably some RISC designs already do this to a limited extent, so implementing it for x86 isn't much of a stretch.
Spoonbender - Wednesday, November 9, 2005 - link
"The main philosophy behind Itanium is, of course, that a compiler can statically schedule instructions much better than a hardware scheduler" - Not always.Of course, the compiler can do all this with the static information within the same translation unit (or in some cases, only within the same basic code block), but not based on runtime behavior. Global optimizations are a pain to implement on a compiler, and a lot of them are simply too complex to even think about, while the hardware scheduler can easily see, for example, where a function is called from, meaning it can figure out some dependencies that might be practically impossible to do in the compiler.
Dynamic and static scheduling can achieve different results based on the different data available to them (at compile-time vs runtime), but it's wrong to say that one is much better than the other. The trick is to use the best of both worlds. x86 compilers already lets the compiler do as much scheduling as possible, and then at runtime the hardware scheduler tweaks everything to fit the particular pipeline, and uses the runtime info available that the compiler didn't have.
Of course, the Itanium could do the same, but relying solely on the compiler is a mistake.
Another disadvantage with the Itanium is that everything becomes a lot more architecture-specific. For example, the same compiler can write decent code for either a P4 or an Athlon 64 (or even a 386).
But because so much of the responsibility for scheduling and instruction bundles is put on the compiler, it's the compiler that has to reflect each particular architecture. So far, there's only Itanium and Itanium 2. What when we get to Itanium 5? Or AMD Athlanium? ;)
Different compilers for each? Or should we accept that the same compiler just generates inefficient code on all other EPIC CPU's than the original target?
And how much headroom does the architecture have then?
(What if in the future we want wider instruction bundles? Or if they find out that reaing bigger amounts of smaller bundles is more efficient? Or if they want to remove some of the current restrictions on instruction order inside a bundle?
I just can't see how EPIC can ever become a viable long-term architecture. And honestly, I don't want to go back to the old days of "New CPU? Have to recompile everything. Binary compatibility? What's that?"
JohanAnandtech - Wednesday, November 9, 2005 - link
You bring up very valid points that I will definitely address in a follow up. Indeed statically scheduling is not always better than dynamically. Most of the time it is, as you can look ahead much more far ahead, but it is less flexible.x86 compilers can never extract much ILP as they are limited by the ISA. With 20% branches and 8 registers, your options are very limited.
But your comment about binary compatibility is a mistake. The 128 bit bundle hasn't changed, so your binary compatibility is saved. It is true that the Itanium 2 can use bundles that the Itanium can't, but the same can be said about the P4 using SSE-2 instructions that the Pentium II can't use. You just provide two codepaths in the same code like we do now in apps where you can enable or disable SSE. Secondly, there are almost no Itanium I out there, so it is sufficient to make your code Itanium 2 compatible.
Wider bundles aren't going to happen. There is no reason to do so, as the groups of independent instructions can be as large as you want, you chain bundles together via the template. Montecito is perfectly compatible with Madison and mckinley
mkruer - Wednesday, November 9, 2005 - link
<mindless ramblings>I think one of the key things to point out is that the current x86 has very little in common with the original ISA, and that the ISA has been adapting over time. The current internal cores are more like RISC then the original CISC design which will probably lead to some low level VLIW implementation mainly in the area of the FP units.
My predictions are that we are going to start seeing some low level implementations of VLIW most likely as a sub core options at first. As time progresses we will see those sub cores become more and more powerful and functional, and as time progresses more and more of the current x86 ISA will fall off to be replaced by an updated x86 ISA. </mindless ramblings>
saratoga - Wednesday, November 9, 2005 - link
Yes very little in common aside from almost complete binary compatability. You're confusing ISA (the binary format for operations) with microarch (the layout of transistors in a processor).Also, "low level VLIW", WTF?
Brian23 - Wednesday, November 9, 2005 - link
If Intel would drop the x86 compatability, L3 cache, and up the L1 and L2 chaches significantly and add an on die memory controller, this chip would be incredable. Then they could do something like transmetta did for backwards compatability until they can coax MS to write an os and compiler that runs natively on chip. At that point x86 would be dead.JohanAnandtech - Wednesday, November 9, 2005 - link
If they up the L1 and L2, it would result in higher latencies. Right now, the L1-cache has a 1 cycle L1. So L1-accesses are as good as free, you don't want that to change for an in-order CPU.The L3-cache is important as it lowers the accesses to the memory significantely. But I agree that x86 hardware support should be dropped, and only software emulation should be available. That opens up a few million transistors that can be used for a primitive OOO system or improved prefetching.
highlandsun - Wednesday, November 9, 2005 - link
As a server chip there's really no reason to beg MS for anything. Linux and gcc can take it from here. Note that big Itanium servers from HP and SGI all run Linux anyway, MS is irrelevant in this space. But yes, they really ought to jettison the x86 baggage. In an open source world there's no need to do on-chip emulation to execute legacy binaries - just recompile the source and get a native binary instead.PeteRoy - Wednesday, November 9, 2005 - link
YEahIntelUser2000 - Wednesday, November 9, 2005 - link
Johan, Do you know that the 30% performance advantage is SoEMT only on Montecito??? Not comparing against Madison??Whether by major compiler improvements or core improvements, Montecito should be 25% faster per clock, per core over Madison.
Its sad that Intel had problems with Montecito. At 2GHz it would have been amazing.