NVIDIA Announces CUDA 6: Unified Memory for CUDA
by Ryan Smith on November 14, 2013 9:00 AM EST
Kicking off next week will be the annual International Conference for High Performance Computing, Networking, Storage, and Analysis, better known as SC. For NVIDIA, next to their annual GPU Technology Conference, SC is their second biggest GPU compute conference, and is typically the venue for NVIDIA’s summer/fall announcements. To that end NVIDIA has a number of announcements lined up for this year, so many in fact that they’re pushing out some of them ahead of the conference just to keep them from being overwhelming. The most important of those announcements in turn will be the announcement of the next version of CUDA, CUDA 6.
Unlike some prior CUDA releases, NVIDIA isn’t touting a large number of new features for this version of CUDA. But what few elements NVIDIA is working on are going to be very significant.
The big news here – and the headlining feature for CUDA 6 – is that NVIDIA has implemented complete unified memory support within CUDA. The toolkit has possessed unified virtual addressing support since CUDA 4, allowing the disparate x86 and GPU memory pools to be addressed together in a single space. But unified virtual addressing only simplified memory management; it did not get rid of the required explicit memory copying and pinning operations necessary to bring over data to the GPU first before the GPU could work on it.

With CUDA 6 NVIDIA has finally taken the next step towards removing those memory copies entirely, by making it possible to abstract the memory management away from the programmer. This is achieved through the CUDA 6 unified memory implementation, which implements a unified memory system on top of the existing memory pool structure. With unified memory, programmers can access any resource or address within the legal address space, regardless of which pool the address actually resides in, and operate on its contents without first explicitly copying the memory over.
Now to be clear here, CUDA 6’s unified memory system doesn’t resolve the technical limitations that require memory copies – specifically, the limited bandwidth and latency of PCIe – rather it’s a change in who’s doing the memory management. Data still needs to be copied to the GPU to be operated upon, but whereas CUDA 5 required explicit memory operations (higher level toolkits built on top of CUDA withstanding) CUDA 6 offers the ability to have CUDA do it instead, freeing the programmer from the task.

The end result as such isn’t necessarily a shift in what CUDA devices can do or their performance while doing it since the memory copies didn’t go away, but rather it further simplifies CUDA programming by removing the need for programmers to do it themselves. This in turn is intended to make CUDA programming more accessible to wider audiences that may not have been interested in doing their own memory management, or even just freeing up existing CUDA developers from having to do it in the future, speeding up code development.
With that said NVIDIA isn’t talking about the performance impact at this time. Memory abstractions such as these typically have some kind of performance penalty over manual memory management – after all, who knows more about the memory needs of an application than an application itself – but of course manual memory management isn’t going anywhere, as there will still be scenarios where the higher complexity is worth the tradeoff.
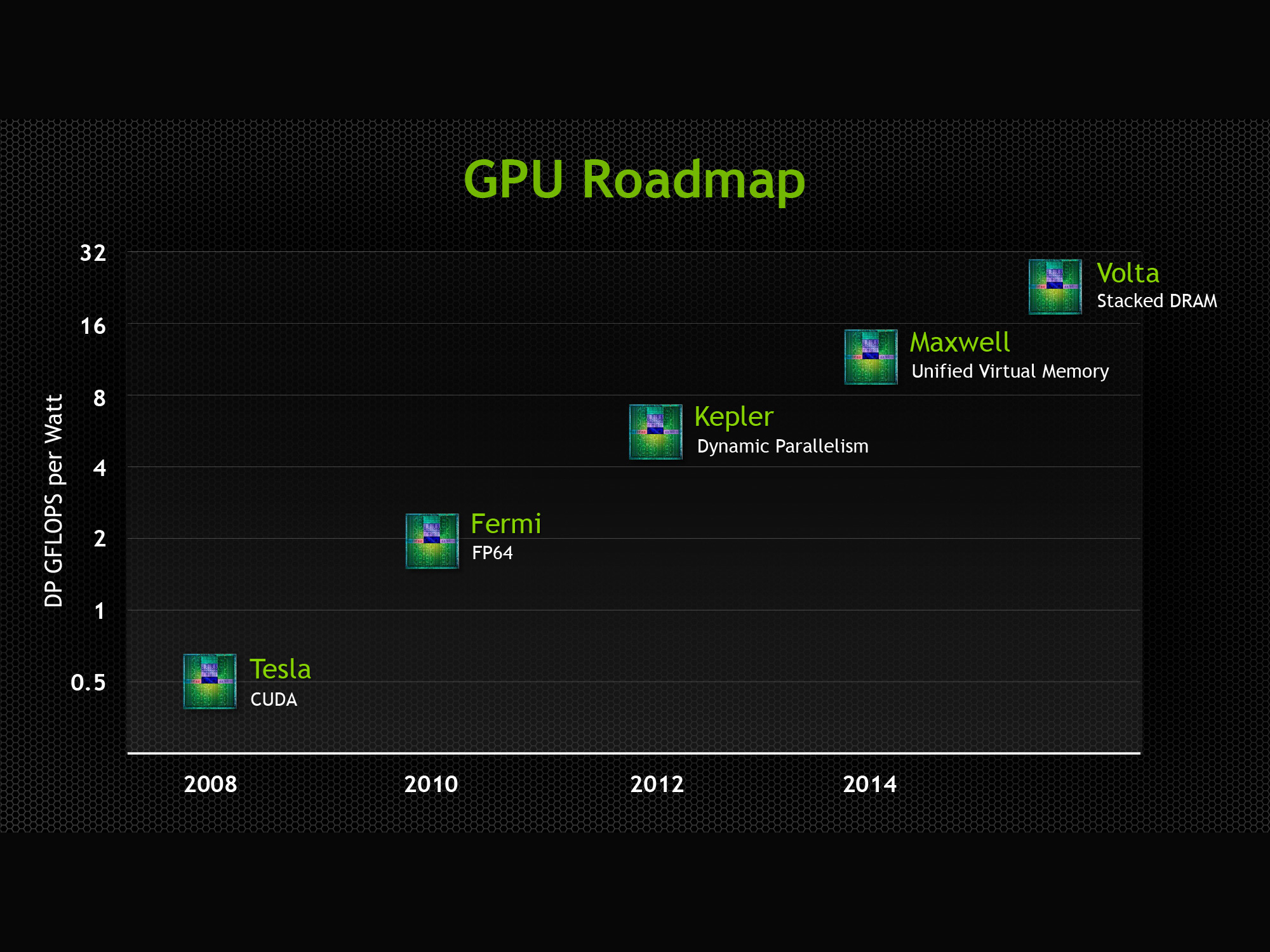
Meanwhile it’s interesting to note that this comes ahead of NVIDIA’s upcoming Maxwell GPU architecture, whose headline feature is also unified memory. From what NVIDIA is telling us they developed the means to offer a unified memory implementation today entirely in software, so they went ahead and developed that ahead of Maxwell’s release. Maxwell will have some kind of hardware functionality for implementing unified memory (and presumably better performance for it), though it’s not something NVIDIA is talking about until Maxwell is ready for its full unveiling. In the interim NVIDIA has laid the groundwork for what Maxwell will bring by getting unified memory into the toolkit before Maxwell even ships.
Moving on, there are a pair of further, smaller additions that will be coming to CUDA with CUDA 6. The first of these is that CUDA 6 will come with new BLAS and FFT libraries that are further tuned for multi-GPU scaling, with these new libraries supporting scaling of up to 8 GPUs in a node. Meanwhile NVIDIA will also be releasing drop-in compatible libraries for BLAS and FFTW, allowing applications that use those libraries to use the GPU accelerated version of their respective routines just by replacing the library.
Wrapping things up, NVIDIA will be showing off CUDA 6 and the rest of their announcement at SC13 next week. Meanwhile we’ll be back on Monday with coverage of the rest of NVIDIA’s SC13 announcements.








43 Comments
View All Comments
Kevin G - Thursday, November 14, 2013 - link
OpenGL was designed in the 90's and it carries some architectural baggage from that era. The Khronos group has insisted on backwards compatibility for OpenGL as the API continues to evolve. Thus in order to trim the fat from the API and optimize for modern architectures, a clean break is necessary.invinciblegod - Thursday, November 14, 2013 - link
Well, first your screenname sort of makes anything you say on the topic suspect. Second, people blast AMD for having mantle be proprietary also (like techreport). However, mantle has a performance advantage. Does cuda perform better than opencl?ddriver - Thursday, November 14, 2013 - link
Last time I checked OpenCL performance was slightly better. CUDA is only faster to compile kernels.AMDshit - Thursday, November 14, 2013 - link
On which AMD piad software? http://media2.hpcwire.com/hpcwire/CUDA_OpenCL_comp...Spunjji - Thursday, November 14, 2013 - link
"Note that performance is, in most cases, close to equivalent".I'm sorry, you were trying to prove what now? :D
ddriver - Thursday, November 14, 2013 - link
nvidia deliberately downplays opencl performance on their hardware to make cuda artificially more "attractive" - because cuda only works on nvidia and opencl works almost everywhere. opencl compute on radeons completely trashes nvidia gpus in the same price range, regardless if they use opencl or cudaalso, this chart actually shows cuda no better than opencl across the board, the few tests where cuda scored better is only because the opencl implementation was incomplete and parts of the workload ran in software rather than in hardware
Spunjji - Thursday, November 14, 2013 - link
I'm not sure how you felt that was relevant, but I'm hopeful that a mod will find and destroy your posts before too long.ddriver - Thursday, November 14, 2013 - link
fat chanceMorawka - Thursday, November 14, 2013 - link
i wouldn't touch any open standard that apple has a hand in making/developing.ddriver - Friday, November 15, 2013 - link
I too despise apple with a passion, but this is not proprietary, apple can only contribute to OpenCL and only with features the entire standard commission agrees with, apple do not have the power to spoil OpenCL in any way.OpenCL works on pretty much every CPU with SIMD, on pretty much every desktop GPU, on recent modern and future ARM chips, even can be implemented in hardware on FPGAs.
There is no reason to dismiss OpenCL because of apple's involvement, surely, apple is a nasty corporation, but so is nvidia, they just were never in the position to be that insolent, but then again, look at the price of titan...
Fact is, apple's involvement or not, OpenCL is the best thing available, it is an open standard, it is not vendor limited and it is beyond the power of any corporation to spoil it.
So if you refuse to "touch" OpenCL, you have even more reasons to refuse to touch cuda, which means you willingly agree to miss out on the tremendous benefits of the power of GPUs, which I doubt you will. Adobe have already scrapped cuda for OpenCL, and due to its portability, vendor and platform independence, OpenCL is yet to gain more ground and come with every application that requires serious numbrer crunching.