LINPACK: Nehalem vs Shanghai part 2
by Johan De Gelas on December 1, 2008 12:00 AM EST- Posted in
- IT Computing general
The last post generated some very interesting comments and questions, which I wanted to address. Unfortunately, some people misinterpreted the post as a "the best scores Nehalem and Shanghai can get in Linpack" review.
So let me make this very clear: this and the previous blogpost are not meant to be a "buyer's guide". The Nehalem desktop system and AMD "Shanghai" server are completely different machines, targeted at totally different markets. Normally, we should wait for the Xeon 5500 to run these kind of benchmarks, but consider this a preview out of curiosity.
Secondly, we were not trying to get the highest possible LINPACK scores on both architectures. We wanted to use one binary which has good optimizations for both AMD's and Intel CPU's. Fully optimized binaries won't even run on the other CPU.
Our only goal is to get an idea how the Nehalem and Shanghai architectures compare when running a "LINPACK" alike binary which is optimized to run on all machines.
Thirdly, this is not our review of course. This is a blogpost which talks about some of the tests we are doing for the review.
MKL on AMD?
Using the Intel Math Kernel Libraries on an AMD CPU is of course a good way to start some heavy debates. As I pointed out in the last blogpost however, in some cases, the slightly older MKL versions still do a very good job on AMD CPUs when you benchmark with low matrix sizes.
You don't have to take my word for it of course.
Compare the Intel Linpack 9.0 (available mid 2007) with the binary that AMD produced at the end of 2007. AMD made a K10 only version using the ACML version 4.0.0, and compiling Linpack with the PGI 7.0.7 compiler (with following flags: pgcc
-O3 -fast -tp=barcelona-64).
All the benchmarks below are done on one CPU with 4 GB (AMD, Intel Xeon) or 3 GB (Intel Core i7). Speedstep, Powernow! and Turbo mode were disabled.
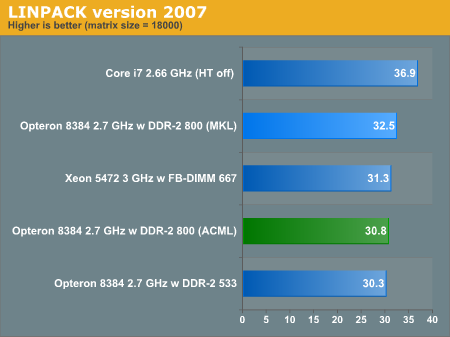
As predicted, the ACML binary which was compiled with 2007 compiler is slower than the MKL "2007" version also compiled in 2007. The MKL version runs on any CPU that has support for (S)SSE-3, so it continues to be a very interesting one for us to test. As you can clearly see from the Xeon 5472 (3 GHz) score, it is not fully optimized for the latest 45 nm Intel CPUs with SSE-4. It is a good "not too optimized" version which can be used on both Intel and AMD CPUs. You can clearly see this as the 3 GHz Xeon 5472 is behind the AMD Opteron 8384. If this Intel Binary was giving the AMD CPUs a badly optimized code path, this would not be possible.
As we move forward to 2008, we have to create a new binary as both AMD and Intel's fully optimized Linpack versions will not run on the competitor's CPU. Intel released the Linpack benchmark version 10.1, which is not fully optimized for the "Nehalem" architecture, but for 45 nm "Harpertown" family.
AMD has created a new Linpack binary using ACML 4.2 and the PGI 7.2-4 compiler. Below you see how the two CPUs compare.
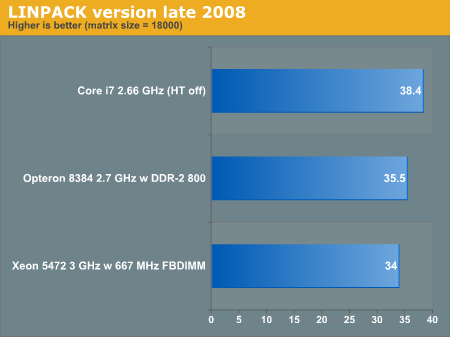
Bottom line is that these LINPACK benchmarks are moving targets like the SPEC CPU benchmarks, as the compilers and libraries used are just as important as the CPUs.When the Xeon 5500 will materialize, LINPACK performance will probably be higher as the binary is built for the "Penryn/Harpertown" family.
While it is useful for the HPC people to see which CPU + compiler can offer the best performance, it is also interesting to understand what kind of performance you get when you compile binaries that have to run on all current CPUs. It is pretty hard to compare CPU architectures if you are using totally different binaries.
In the next post we'll delve a bit deeper on what is happening with Hyperthreading, Linpack and the new architectures.








31 Comments
View All Comments
kmmatney - Tuesday, December 2, 2008 - link
Bye - Don't let the door hit your ass.strikeback03 - Tuesday, December 2, 2008 - link
good, the more fanbois that disappear the betterMamiyaOtaru - Tuesday, December 2, 2008 - link
yayerikejw - Tuesday, December 2, 2008 - link
If you really wanted to compare architectures you would not use the Intel binary even if it faster for AMD than other binaries.You would choose a binary that was not heavily optimized at all and would not benefit any architecture.
The scores would be lower but you would compare ARCHITECTURES.
Then it is up to software developers to create the most efficient binary for the platform of choice. That is a completely different matter.
Do you really beleive that the Intel binary would not be better suited for Intel processors?
If they were not better the Intel developers would be worthless and incompetent, I think they are not.
JohanAnandtech - Sunday, December 7, 2008 - link
Remember that AMD always takes in account that a lot of code out there is optimized for Intel architectures. If Intel's engineers go all the way to produce a carefully optimized SSSE-3 binary, it is very possible that it performs very well on the K10. And the evidence shows that the one I have been using is very good, as Shanghai at 2.7 GHz outperforms the Xeon 5472 at 3 GHz.Zorblack1 - Monday, December 1, 2008 - link
Look at all these hateful peeps...Zorblack1 - Monday, December 1, 2008 - link
grrrhttp://anandtech.com/weblog/showpost.aspx?i=528">http://anandtech.com/weblog/showpost.aspx?i=528
Toadster - Monday, December 1, 2008 - link
very interesting... when can we buy some? :)ZootyGray - Tuesday, December 2, 2008 - link
AT THE i7 TLB error DISCOUNT STOREthat'll rock your house.
BlueBlazer - Tuesday, December 2, 2008 - link
Go back to your UAEZone.So called bug FUD was debunked.
http://www.techreport.com/discussions.x/15979">http://www.techreport.com/discussions.x/15979