The Xserve Server Platform
The most surprising and even astonishing results of the previous article were, of course, the MySQL and Apache server benchmarks. A powerful Windows XP based client (see above: "Client Configuration: Dual Opteron 250") fires off an enormous amount of Select, grouping and ordering read intensive queries and simulates 1 to 50 concurrent clients. All that query data is sent over a direct Gigabit Ethernet link to the tested server; in this case, a PowerMac Dual G5 2.5 GHz running OS X Server (Tiger). In part I, we discovered that performance of the Apple machine completely collapsed once there were more than 2 concurrent clients.The solution? Install a Linux distribution to verify our suspicion that the OS is to blame is on the mark. We chose Yellow Dog Linux (YDL). Terra Soft, the company behind Yellow Dog, is an Apple Authorized OEM Value Added Reseller, so you could say that Apple has no objection to installing YDL on your Apple machines. There is more: Terra Soft is specialized in optimizing for the G5 processor. The version that we used, Yellow Dog Linux 4.0.1, is based on the Linux Kernel version 2.6.10-1.ydl.1g5-smp.
Let us see how the Dual 2.5 GHz G5 performed in MySQL when running Yellow Dog Linux. Please note: YDL 4.0 wouldn't run on the 2.7 GHz Apple machine, so we do not have results for that platform.
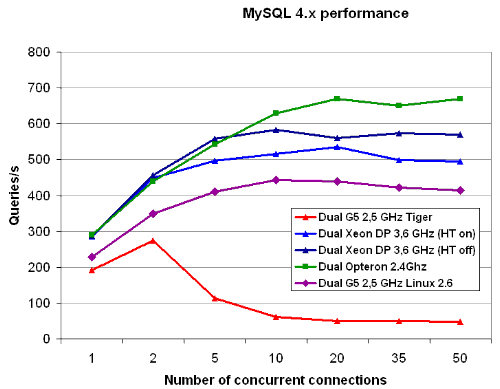
While the G5 is not the best integer processing unit out there, it is not the one to blame for the poor performance that we experienced in our first tests. Running Yellow Dog Linux, the Dual G5 was capable of performing similar to a 3 GHz Xeon. Notice that more concurrent connections gives better performance from 1 to 20. At 5 concurrent simulated users, YDL simply wipes the floor with Mac OS X: 411 versus 113 queries per second. It gets worse at 10 concurrent users: 443 queries per second on Linux versus 62 on Mac Os X. Around 20 connections, performance declines only very slowly just like all the x86/Linux machines.
With the MySQL performance woes now clearly caused by OS X, let us see if Apache tells us the same story. We tested with Apachebench, with "n" being the total of number of connections and "c" the total of concurrent connections:
ab -n 100000 -c 100 http://localhostSome people suggested that we should test with both Apache 1.3 and 2.0, so we gave Apache 2.0 a test run.
| Unit: Requests per second | Powermac Dual G5 2.5 GHz OS X | Powermac Dual G5 2.5 GHz YDL | Dual Xeon 3.6 GHz |
| Apache 1.3 | 250 | 709 | 1291 |
| Apache 2.0 | 266 | 2165 | 3410 |
On OS X, we noticed that the activity monitor was telling us that the CPUs were not working very hard and were underutilized. This seems to indicate that the problem with Apache is somewhat different from MySQL, as MySQL showed a CPU load between 165% and 190%. (200% is the maximum, as there are 2 CPUs in the system.)
Apple told us that the problem lies in Apachebench (the client side), which stalls from time to time and thus generates too low of a load on the (Apache) server. The weird thing is that this does not happen with few connections (up to 10,000). When we repeated the test, Apachebench on Mac OS X gets in trouble again. Version 2.0 is slightly faster on OS X, but it still trails by a significant margin. On the other hand, YDL and the Xeon platform are roughly 3X as fast with version 2.0.
According to Apple, this is a bug in Apachebench. Now, we can accept that explanation, as it is clear that the server is not loaded and can still accept a lot more web requests. However, the Apachebench problem is still interesting. Why exactly does the client stall? Is it really a bug or is it running out of some resources? We didn't delve deeper, as we are developing a less synthetic, closer to the real world benchmark to test web servers.
Even if we ignore the Apache results, our MySQL tests - and the queries used in these tests - are based on a real world usage pattern of a real world database. The G5 is partially crippled by a chipset that takes a long time to access the memory, and it's not the fastest integer CPU; still, it performs like a 3 GHz Xeon on Linux. The problem clearly lies in Mac OS X, and is worth further investigation.








47 Comments
View All Comments
Gandalf90125 - Friday, September 2, 2005 - link
From the article:"...so it seems that IBM, although slightly late, could have provided everything that Apple needs."
I'd say not everything Apple needs as I suspect the switch to Intel was driven more by marketing than any technical aspect of the IBM vs. the Intel chips.
Illissius - Friday, September 2, 2005 - link
A few notes:- you mention trying a --fast-math option, which I've never heard of... presumably this was a typo for -ffast-math?
- when I tried using -mcpu (which you say you used for YDL) on GCC 3.4, it told me the option had been deprecated, and -mtune has to be used instead (dunno whether it told me this latter part itself or I read it somewhere else, but it's true). I'm not sure whether GCC4 has the same behaviour (I'd think so), whether it still has the intended effect despite the warning, or whether it matters at all.
- was there a reason for using -march on one, and -mcpu/-mtune on the other? (the difference is that -mcpu/-mtune optimize the code for that processor as much as possible while still keeping the code compatible with everything else in the architecture, while -march does the same without care for compatibility -- on x86 at least, not sure whether it's the same on PPC)
- you mention using the same compiler because, err, you wanted to use the same compiler... if this was done in the hopes of it generating code of similar speed for each architecture, though, then your own results show there isn't much point -- seems GCC, 3.3 at least, is much better at generating x86 code than PPC (which isn't surprising, given much more work probably went into it due to the larger userbase). Not saying it was a bad idea to use GCC on both platforms (it's a good one, if for no other reason than most code, on the Linux side at least and OSX itself (not sure about the apps) are compiled with it), just that if the above was the reason, it wasn't a very good one ;).
- Continuing the above, I was a bit surprised at the, *ahem*, noticeable difference in speed between not even two different compilers, but two versions of the same. (I was expecting something like 1-5, maybe 10% difference, not 100). Maybe this could warrant yet another followup article, this time on compilers? :)
Pannenkoek - Friday, September 2, 2005 - link
The reason is that GCC 4.0 incorporated infrastrucure for vector optimization (tree-ssa), which can give, especially in synthetic benchmarks, huge increase in FP performance. GCC can now finally optimize for SSE, Altivec, etc., a reason why in the past optimizing specifically for newer Pentiums did not yield much improvement.Althougn compiler benchmarks would be interesting, I doubt it is a task for Anandtech. Normal desktop users do not have to worry about whether or not their applications are optimized optimally, and any differences between, say GCC and ICC, are small or negligible for ordinary desktop programs. (Multimedia programs often have inline assembly for performance critical parts anyway).
GCC is free, supports about any platform and improves continually while it's already a first class compiler.
javaxman - Friday, September 2, 2005 - link
While I generally love this article, I have to wonder...why not write a simple benchmark for pthread(), if you think that's the bottleneck? Surely it'd be a simple thing to write a page of code which creates a bunch of threads in a loop, then issues a thread count and/or timestamp. It seems like a blindingly obvious test to run. Please run it.
I have to say that I *do* think pthread() is the likely bottleneck, possibly due to BSD4.9-derivative code, but why not test that if we think that's the problem? I understand wanting to see real-world MySQL performance, but if you're trying to find a system-level bottleneck, that's not the right type of testing to do...
Now that I metion it, Darwinx86 vs. BSD 4.9 ( on the same system ) vs. BSD 5.x ( on the same system ) vs. Linux ( on the same system ) would really be a more interesting test at this point... I'm really not caring about PPC these days unless it's an IBM blade system, to be honest... testing an Apple PPC almost seems silly, they'll be gone before too long... Apple's decision to move away from PPC has more to do with *future* chip development than *current* offerings, anyway... Intel and AMD are just putting more R&D into their x86 chips, IBM's not matching it, and Apple knows it...
but even if you are going to look at PPC systems, if you're trying to find a system-level bottleneck, write and run system-level tests... a pthread() test is what is needed here.
rhavenn - Friday, September 2, 2005 - link
If I remember correctly, OS X is forked off of the FreeBSD 4.9 codebase. The 4.x series of BSD always had a crappy threading system and didn't handled threaded apps well at all. I doubt Apple really touched those internals all that much.FreeBSD 5.x has a much better time of it. I'm wondering if the switch back to a Intel platform will make it easier for Apple to integrate the BSD 5.x codebase into their OS? or even if they plan on using the BSD 6.x codebase for a future release? The threading models have vastly improved.
Just a thought :)
JohanAnandtech - Friday, September 2, 2005 - link
http://www.apple.com/education/hed/compsci/tiger.h...">http://www.apple.com/education/hed/compsci/tiger.h... :"FreeBSD 5.0
The upgraded kernel in Tiger, based on mach and FreeBSD, provides optimized resource locking for better scalability across multiple processors, support for 64-bit memory pointers through the System library and standards-based access control lists"
Where did you see FreeBSD 4.9?
mbe - Friday, September 2, 2005 - link
Readers also pointed out that LMBench uses "fork", which is the way to create a process and not threads in all Unix variants, including Mac OS X and Linux. I fully agree, but does this mean that the benchmark tells us nothing about the way that the OS handles threading? The relation between a low number in this particular Lmbench benchmark and a slow creating of threads may or may not be the answer, but it does give us some indication of a performance issue. Allow me to explain...This misses the point, your claim in the last article was that MacOS X used userspace threads. Mentioning that LMbench uses processes still rules out userspace threads having any part to play. This is since processes can't in any meaningful way (short of violating some pretty basic principles) be implemented around userspace threads. The point is that a process is a virtual memory space attached to a main system thread, not a userspace thread which are not normally even considered threads on this level.
This is necessary since the virtual memory attached to the thread has to be managed when doing context switches, and by its very definition userspace code cannot directly touch the memory mappings.
JohanAnandtech - Friday, September 2, 2005 - link
Yes, it could be. The interesting questions are:- Is the only culprit for the 8 time lower performance. Microkernels are reported to be 66 to 5% slower depending on who benchmarked it. But not 8 times slower.
- What makes it still interesting for the apple devs to use it?
I hope Apple will be a bit more keen to defend their product, because their might be interesting technical reasons to keep the Mach kernel.
sdf - Friday, September 2, 2005 - link
Is Mac OS X really a microkernel? I understood it to be designed to function as a microkernel, but compiled and shipped as a macrokernel for performance reasons.JohanAnandtech - Sunday, September 4, 2005 - link
I am sorry if I wasn't clear. As I state in the article clearly: Mac OS X is ** NOT ** a microkernel, but based on a microkernel as the Mach kernel is burried inside the FreeBSD monolithic kernel.Most of the tasks are done by a FreeBSD alike kernel, but threading is done by the Mach kernel.