Intel Xeon Sapphire Rapids: How To Go Monolithic with Tiles
by Dr. Ian Cutress on August 31, 2021 10:00 AM ESTThe March of More Silicon: Connectivity Matters
To date, all of Intel’s leading-edge Xeon Scalable processors have been monolithic, i.e. one piece of silicon. Having a single piece of silicon has its advantages, namely a fast in-silicon interconnect between cores but also a singular power interface to manage. However, as we move to smaller and smaller process nodes, having one large piece of silicon has downsides: they are hard to manufacture in volume without defects, which increases cost if you want the high-core count models, but also it ends up being limiting.

The alternative to a large monolithic design is to cut it up into smaller bits of silicon and connect them together. The main advantages here is better silicon yield, but also configurability by having different silicon for different functions as needed. With a multi-die design, you can ultimately end up with more silicon than a monolithic design can provide – the reticle (manufacturing) limit for a single silicon die is ~700-800 mm2, and with a multi-die processor several smaller silicon dies can be put together, easily pushing over 1000mm2. Intel has stated that each of its silicon tiles are ~400 mm2, creating a total around ~1600mm2. But the major downside to multi-die designs is connectivity and power.
The simplest way to package two chips in a substrate together is through intra-substrate connections, or what essentially amounts to PCB traces. This is a high-yielding process, however it has the two drawbacks listed above: connectivity and power. It costs more energy to send a bit over a PCB connection than it does through silicon, but also the bandwidth is much lower because the signals cannot be as densely packed. As a result, without careful planning, a multi-die connected product will have to be aware of how far data is at any one time, an issue few monolithic products have.
The way around this is with a faster interconnect. Rather than putting that connectivity through the substrate, through the package, what if it was through silicon anyway? By placing these connected dies on a piece of silicon, such as an interposer, the connectivity traces have better signal integrity, and better power. Using an interposer, this is commonly referred to as 2.5D packaging. It costs a bit more than standard packaging technology (there’s also scope for active interposers with logic), but we also have another limitation in that the interposer has to be bigger than all the silicon put together. But overall, this is a better option, especially if you want your multi-die product to act as if it were monolithic.

Intel decided that the best way to beat the downsides of interposers but still get the benefits of an effective monolithic silicon design was instead was to create super small interposers that lived inside the substrate. By pre-embedding them in the right location, with the right packaging tools two chips could be placed on this small Embedded Multi-Die Interconnect Bridge (EMIB), and voilà, a system that works as close to a monolithic design as is physically possible.
Intel has worked on the EMIB technology for over a decade. The development has had three major milestones from our perspective: (1) being able to embed the bridge into a package with a high yield, (2) being able to place big silicon die on the bridge at high yield, and (3) being able to put two high-powered die next to each other on a bridge. It is that third part that I think Intel has struggled with the most – by having two high-powered die next to each other, especially if the die have different coefficients of thermal expansion and different thermal properties, there is the potential of weakening the substrate around the bridge or the connections to the bridge itself. Almost all of Intel’s products that used EMIB so far have been around connecting a CPU/GPU to high-bandwidth memory, which is an order of magnitude lower power than what it’s being connected to. Because of that, I wasn’t convinced putting two high-powered tiles together possible, at least until Intel announced a multi-die FPGA connected by EMIB using two high-powered FPGA tiles in late 2019. From that point on, it was only a moment in time before Intel enabled the technology on its CPU product stack. We’re finally getting that with Sapphire Rapids.
10x EMIB on Sapphire Rapids
Sapphire Rapids is going to be using four tiles connected with 10 EMIB connections using a 55-micron connection pitch. Normally you might think that a 2x2 array of tiles would need equal EMIBs per tile-to-tile connection, so in this case with 2 EMIBs per connection, that would be eight – why is Intel quoting 10 here? That comes down to the way Sapphire Rapids is designed.
Because Intel wants SPR to look monolithic to every operating system, Intel has essentially cut its inter-core mesh horizontally and vertically. That way each connection through the EMIB is seen purely as the next step on the mesh. But Intel’s monolithic designs are not symmetric in either of those dimensions – usually features like the PCIe or QPI are on the edges, and not in the same place in every corner. Intel has told us that in Sapphire Rapids, this is similarly the case, and one dimension is using 3 EMIBs per connection while the other dimension is using 2 EMIBs per connection.
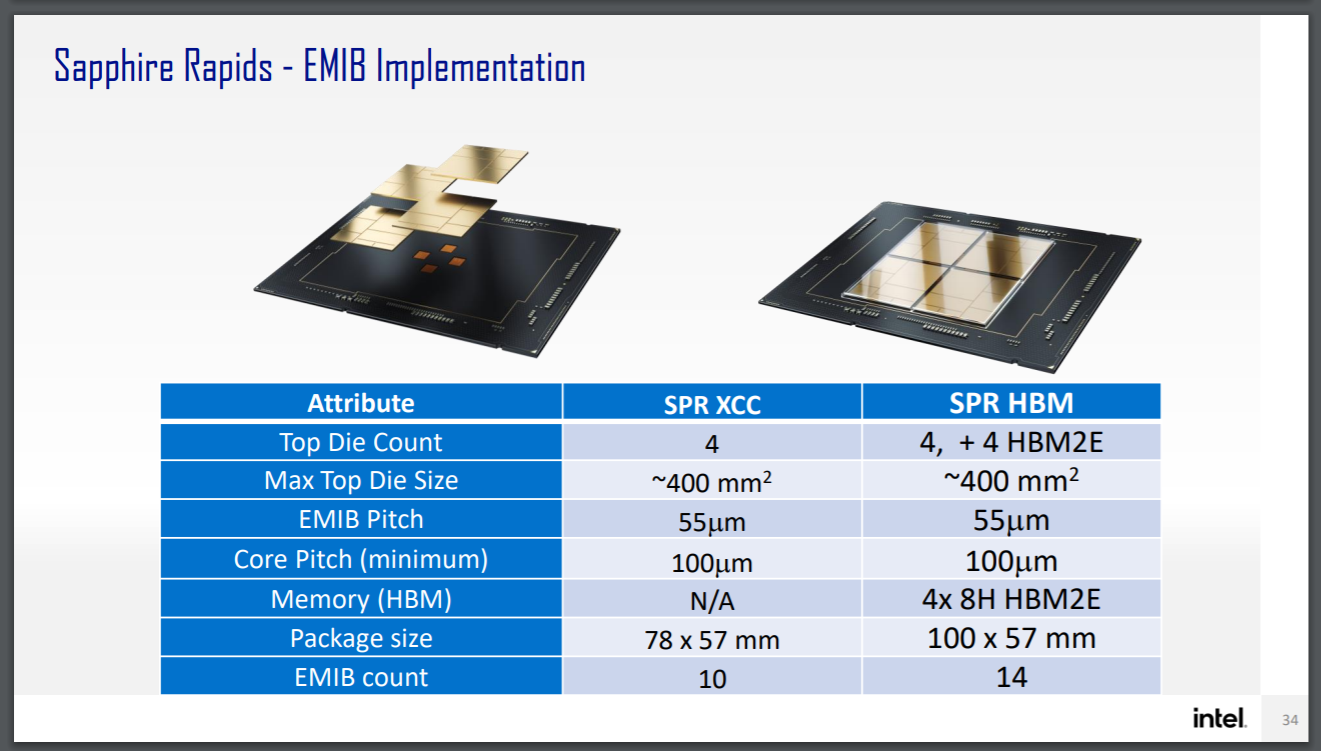
By avoiding strict rotational symmetry in its design, and without a central IO hub, Intel is leaning heavily to acting as a monolithic die – leaning so heavily it’s almost falling over to do so. As long as the EMIB connections are consistent between tiles, software shouldn’t have to worry, although until we get further details here, it’s hard to speculate exactly why without going through the motions of trying to figure out Intel’s mesh designs and how the extra parts all connect together. SPR sounds like a monolithic design cut up, rather than a ground-up multi-die design, if that makes sense.
Intel announced earlier this year that it will make an HBM version of Sapphire Rapids, using four HBM tiles. These will also be connected by EMIB, one per tile.
Tiles Tiles Tiles
Intel did give an insight into what exactly each of the separate tiles will have inside it, however this was extremely high level:

Each tile has:
- cores, cache, and mesh
- A memory controller with 2x64-bit DDR5 channels
- UPI links
- Accelerator links
- PCIe links
In this situation, and throughout the presentation, it looks like all four tiles are equal, with the rotational symmetry I mentioned above. To make silicon that does this, in the way presented, isn’t as easy as mirroring the design and printing that onto a silicon wafer. The crystal plane of the wafer limits how designs can be built, and so any mirroring has to be redesigned completely. As a result, Intel confirmed that it has to use two different sets of masks to build Sapphire Rapids, one each for the two dies it has to make. It can then rotate each of these two dies to build the 2x2 tile grid as shown.
It’s worth comparing this to AMD’s first-generation EPYC, which also used a 2x2 chiplet method, albeit with connectivity through the package. AMD escaped the need for having multiple silicon designs by having it rotationally symmetric – AMD built four die-to-die interfaces on the silicon, but only used three for each rotation. It’s a cheaper solution (and one that was right for AMD’s financial situation at the time) at the cost of die area, but also enables a level of simplicity. AMD’s central IO die method in newer EPYCs moves away from this issue entirely. From my perspective, it’s something Intel is going to have to move towards if they want to scale beyond SPR but also for a different reason.
As it stands, each of the tiles holds 128-bits of DDR5 memory interfaces, for a total of 512-bits across all four tiles. Physically, this means we will see eight 64-bit memory controllers* for either eight or sixteen memory modules per socket in a system. That’s perfectly fine for versions of Sapphire Rapids with all four compute tiles.
However, we know that the Sapphire Rapids processor offering is going to have to scale down to fewer cores. In the past, Intel would create three different silicon monolithic variations to cater for these markets and optimize silicon output, but all the processors would have the same memory controller count.
This means that if SPR is going to offer versions with fewer cores, it is going to either create dummy tiles without any cores on them, but still keep the PCIe/DDR5 as required, or quite simply those lower core counts are going to have fewer memory controllers. That’s going to be a pain for system manufactures who want to build catch-all systems, because they’re going to have to build for both extremes.
The other alternative is that Intel has monolithic versions of SPR with all 8 memory channels for lower core count designs. But at this time, Intel has not disclosed how it is going to cater to those markets.
*technically DDR5 puts two 32-bit channels on a single module, but as yet the industry doesn’t have a term to differentiate between a module with one 64-bit memory channel on it vs. a module with two 32-bit memory channels on it. The word ‘channel’ has often been interchangeable with ‘memory slot’ to date, but this will have to change.








94 Comments
View All Comments
Spunjji - Tuesday, August 31, 2021 - link
So...Lots of cores probably, but we don't know how many.
No word on costs, but 4 large dies on a process that has yet to yield well + EMIB with high-power chips + double the number of masks required for the product doesn't speak to being economical.
CXL 1.1, only not exactly, just bits of it.
Lots of AI-friendly stuff, but people are already doing AI stuff on dedicated accelerators.
Moar Sockits, though! Whee!
Honestly, I'm a little concerned. This looks like it's going to be wildly expensive and not very compelling. I hope the smaller dies are a little less absurd.
Kamen Rider Blade - Tuesday, August 31, 2021 - link
According to leaks, 14 Cores per Tile is the Max / (100%) yield.2 of the spots that would be used for a 4x4 2D-array of cores is used for Inter-connect management.
repoman27 - Tuesday, August 31, 2021 - link
Someone has already disassembled and posted images of a Sapphire Rapids XCC engineering sample: https://www.bilibili.com/read/cv11692201 The SPR XCC SKUs are expected to top out at 56 cores, however, the individual dies clearly feature a 4x4 grid with 15 CPU core tiles plus an IMC tile (for the two DDR5 controllers). The dies are 426 mm², and according to the roadmaps at least one CPU core per die will be disabled.Intel typically produces three floorplan designs for each Xeon Scalable generation, e.g. XCC, HCC, and LCC. While they are burning two tape-outs with the left and right XCC dies for SPR, there is also supposedly an up to 34 core MCC product in the works. If Intel were to add another column to the XCC die—three more CPU core tiles and another IMC tile—they would end up with an 18-core die with four memory channels. A two die package would have up to 36 cores (or 34 with at least one core disabled on each die) and still have 8-channel memory. An 18-core, 4-channel HEDT or workstation product would also be possible using a single die.
Spunjji - Tuesday, September 7, 2021 - link
Interesting. That would certainly help to fill out a bunch of products further down the line, but wouldn't it also require double the masks to produce a mirror design of the die?Still, it (alongside the process improvements) should at least help end the yield problems they've had with Ice Lake SP.
WaltC - Tuesday, August 31, 2021 - link
I always get a kick these days to see "Intel's Process 7" stated with a straight face and no qualifier. Trying desperately to achieve some sort of marketing-level process equality with AMD/TSMC (who can unashamedly and accurately say "7nm".) This is what "we're behind" marketing looks like, I guess. Intel seems to have learned a lot from its previous association with Apple--well, at least in terms of marketing...;)WaltC - Tuesday, August 31, 2021 - link
Wanted to add that all of this wordage used to describe vaporware is beginning to remind me of a lot of Larrabee. Although to be fair, I really do think that at some point Intel will have something to sell here...at some point. That'll be nice because then we won't be discussing vaporware any longer.Wrs - Tuesday, August 31, 2021 - link
What if I tell you they're technically close to equivalent to TSMC 7 and Samsung 5? You can specify a process to be as advanced as you want, the question is whether/how well you can build it. Originally what was called Intel 10nm was very ambitious, way better than TSMC's 10nm. Only it would take Intel 7 years in between nodes rather than the expected 2-3, giving TSMC all the time to catch up and more. Today TSMC is in pole position - we're just waiting for their 5 to mature to reach desktop/server power density.Calin - Wednesday, September 1, 2021 - link
The "nanometers" you're so faithful to are just a small bit of the entire wafer-to-microprocessor saga. Intel, Global Foundries (ex-AMD), TSMC, Samsung and the others have different measurements in all of these areas, and some production choices are better than other.The "Feature Size" (the so-called nanometers) is not the only "measuring stick" - you also have vias (i.e. the width of the electrical connections), the uniformity with which you can produce something (leading to a lower voltage overall, as there are no "outliers" that need that extra voltage to work), ...
As for "transistor density" - this varies across processes and process variants, and is also affected by the "library" (high density or low density - one for the most transistors at lower power, the other with less transistors on the same area but it has better frequency and can cool a higher power-per-transistor).
Anyway, here's an article with helpful pictures - Intel 10nm is relatively similar to TSMC 7nm in density, it's below just by a bit and not by the 49% straight math would suggest (i.e. 10x10=100 transistors in a 70nmx70nm square for TSMC and 7x7=49 transistors for Intel 10nm).
https://hexus.net/tech/news/cpu/145645-intel-14nm-...
Foeketijn - Wednesday, September 1, 2021 - link
I agree, but like to add Intels 10nm is about as small as the TSMC 7nm. It's like, at what height do you measure the treetrunks width.drothgery - Wednesday, September 1, 2021 - link
Process names have been marketing, not measurements of any actual feature size since they were naming processes by microns. And others have noted that what Intel's calling Intel 7 now is pretty similar density to TSMC N7 for CPUs. I'd also note that TSMC's actual name for what's commonly called their "7nm" is "N7", not "7nm"; no nanometers there either.