Arm Announces Ethos-N78 NPU: Bigger And More Efficient
by Andrei Frumusanu on May 27, 2020 10:00 AM EST
Yesterday Arm released the new Cortex-A78, Cortex-X1 CPUs and the new Mali-G78 GPU. Alongside the new “key” IPs from the company, we also saw the reveal of the newest Ethos-N78 NPU, announcing Arm’s new second-generation design.
Over the last few years we’ve seen a literal explosion of machine learning accelerators in the industry, with a literal wild west of different IP solutions out there. On the mobile front particularly there’s been a huge amount of different custom solutions developed in-house by SoC vendors, this includes designs such as from Qualcomm, HiSilicon, MediaTek and Samsung LSI. For vendors who do not have the design ability to deploy their own IP, there’s the possibility of licensing something from an IP vendor such as Arm.
Arm’s “Ethos” machine learning IP is aimed at client-side inferencing workloads, originally described as “Project Trillium” and the first implementation seeing life in the form of the Ethos-N77. It’s been a year since the release of the first generation, and Arm has been working hard on the next iteration of the architecture. Today, we’re covering the “Scylla” architecture that’s being used in the new Ethos-N78.

From a very high-level view, what the N78 promises is a quite large boost both in performance and efficiency. The new design scales up much higher than the biggest N77 configuration, now being able to offer 2x the peak performance at up to 10TOPs of raw computational throughput.
Arm has revamped the design of the NPU for better power efficiency, enabled through various new compression techniques as well as an improvement in external memory bandwidth per inference of up to 40%.

Strong points of the N78 are the IP’s ability to scale performance across different configuration options. The IP is available at 4 different performance points, or better said at four different distinct engine configurations, from the smallest config at 1TOPs, to 2, 5 and finally a maximum of 10TOPs. This corresponds to MAC configurations of 512, 1024, 2048 and 4096 units for the totality of the design.
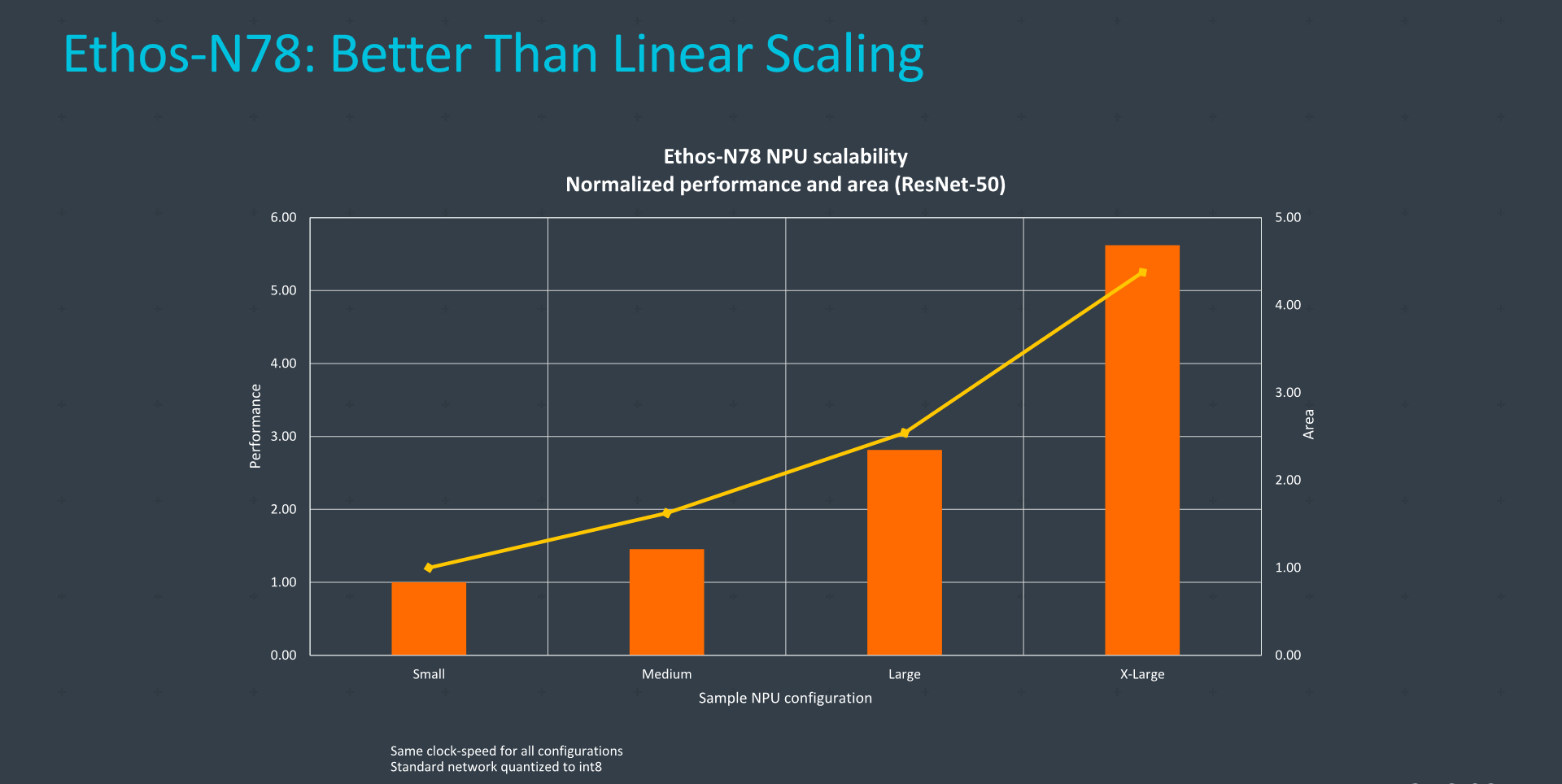
The interesting aspect of scaling bigger is that the area efficiency of the IP actually scales better the bigger the implementation, due to probably the fact that the unique fixed shared function blocks area percentage shrinks with the more computation engines the design has.
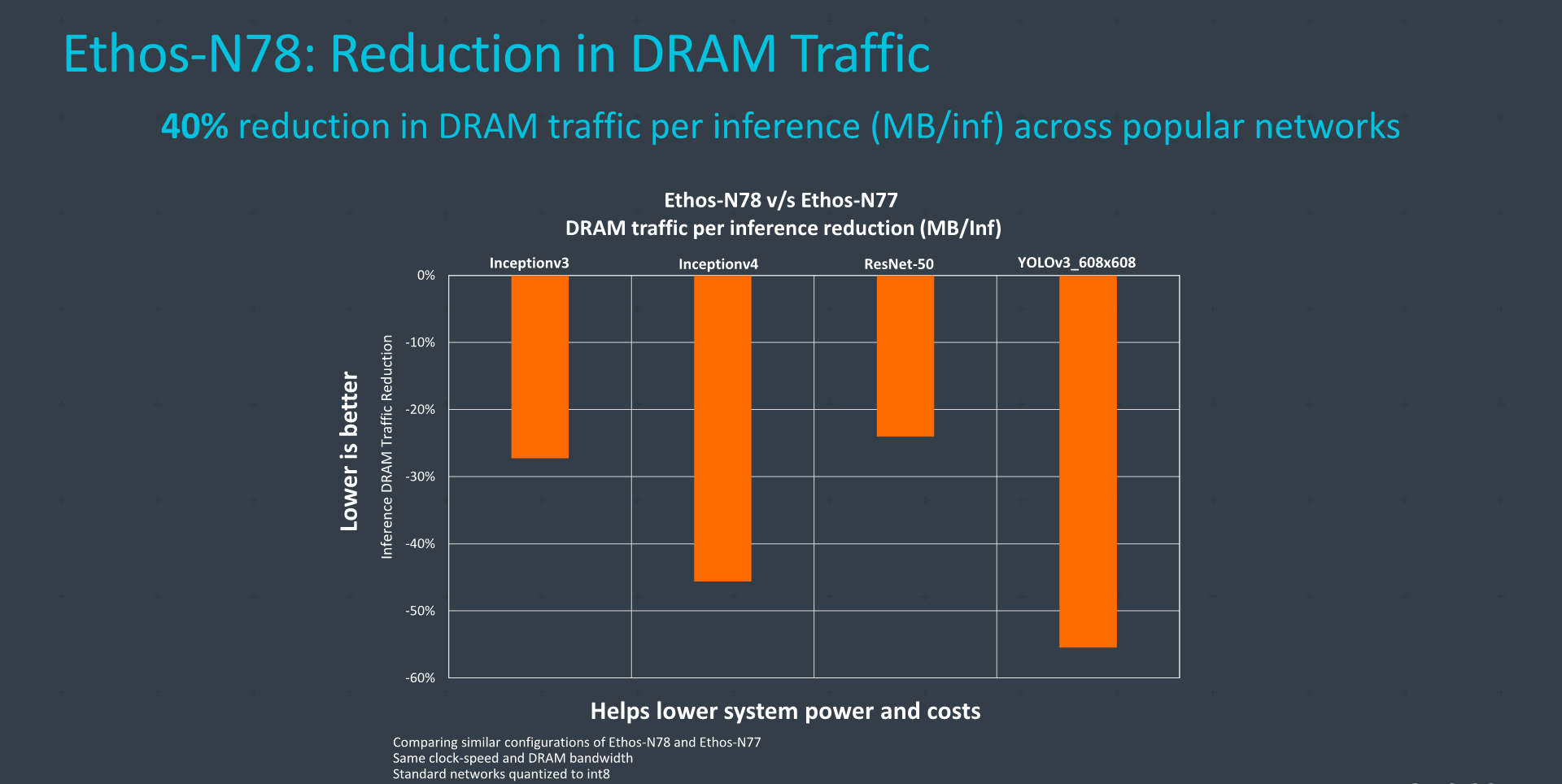
Architecturally, the biggest improvements of the new N78 were in the way it handles data around in the engines, enabling new compression methods for data that not only goes outside the NPU (DRAM bandwidth improvement), but also data movement within the NPU itself, improving efficiency for both performance and power.
The new compression and data handling can significantly reduce the bandwidth of the system with an average 40% reduction across workloads – which is an extremely impressive figure to showcase between IP generations.
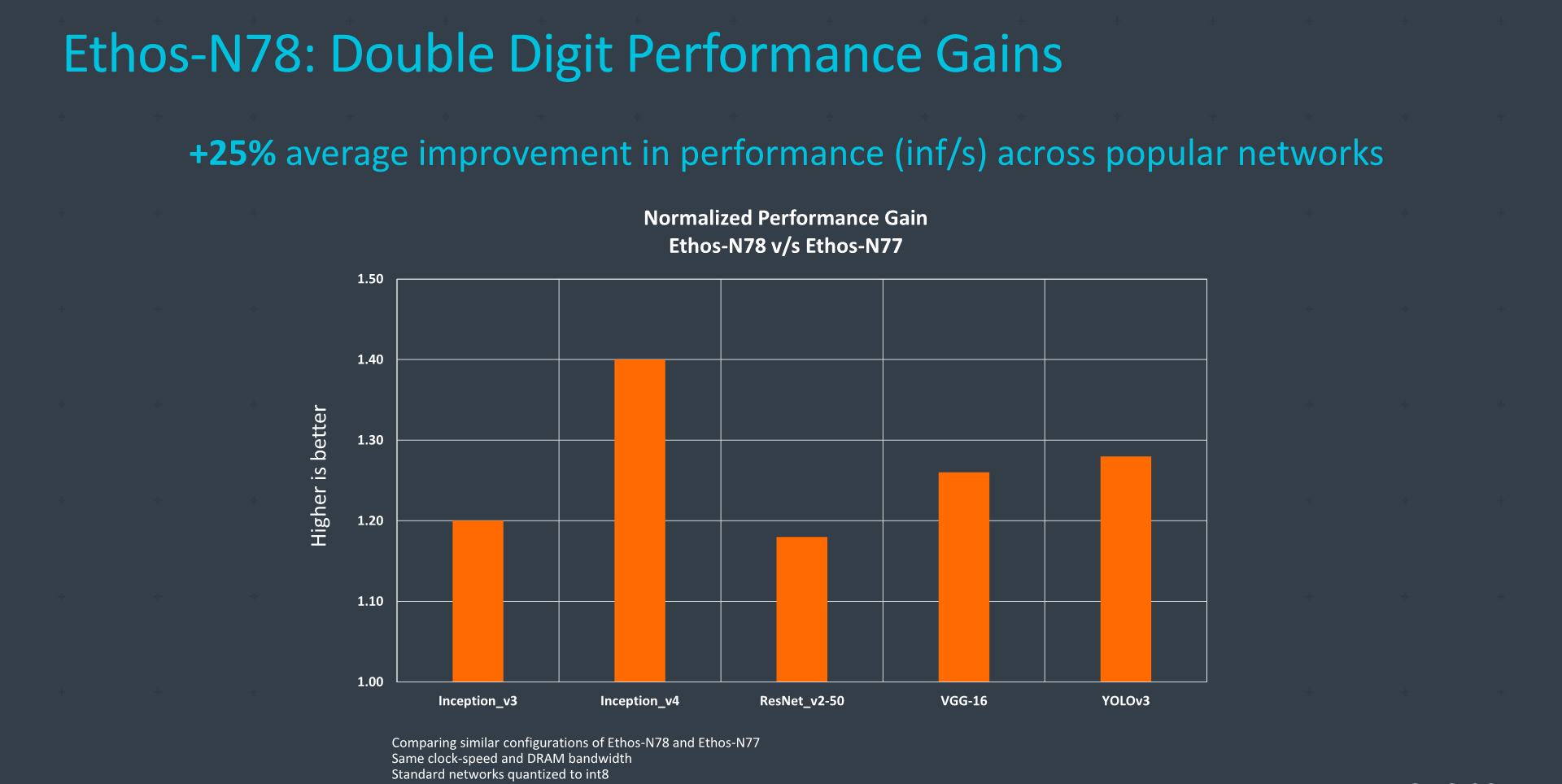
Generational performance uplifts, thanks to the higher performance density and power efficiency are on average 25%, which along with the doubled peak performance configuration means that it has the potential to represent a large boost in end devices.
It’s quite hard to analyse NPUs on how they perform in the competitive landscape – particularly here in Arm’s case given that we haven’t yet seen the first generation NPU designs in silicon. One interesting remark that Arm has made, is that in this space, software matters more than anything else, and a bad software stack can possibly ruin what otherwise would be a good hardware design. Arm mentioned they’ve seen vendors adopt their own Ethos IP and dropping competitor designs because of this – Arm says they invest a very large amount of resources into software in order to facilitate customers to actually properly make use of their hardware designs.
Arm’s new Ethos-N78 has already been licensed out to customers and they’re taping in their designs with it, with likely the first products seeing the light of day in 2021 at the earliest.
Related Reading:
- Arm Announces New Ethos-N57 and N37 NPUs, Mali-G57 Valhall GPU and Mali-D37 DPU
- ARM Details "Project Trillium" Machine Learning Processor Architecture
- Imagination Goes Further Down the AI Rabbit Hole, Unveils PowerVR Series3NX Neural Network Accelerator
- CEVA Announces NeuPro-S Second-Generation NN IP
- Cadence Announces Tensilica Vision Q7 DS








34 Comments
View All Comments
dotjaz - Saturday, May 30, 2020 - link
Except ARM uses MCE blocks, 128 MAC per block, and in both U55 and N77's product briefs it's described as 8x8edzieba - Thursday, May 28, 2020 - link
What in the heck are you all on about?!A 2D matrix is a representation of a 1D tensor, because that's how tensors work. They're mathematical objects, not some Google brand or some nebulous thing that must be 'turned into' a 2D matrix. The matrix is the tensor, that's how it's represented mathematically.
sun_burn - Thursday, May 28, 2020 - link
A tensor is an N-dimensional array. Typically it refers to 3D and 4D tensors. A 1D tensor is a vector. A 2D tensor is a matrix.A 3D tensor is converted into 2D matrix form using techniques like im2col , enabling a 3D convolution to be performed using a 2D matrix multiplication operation. Different NPU designs may or may not choose to do this depending on how they are designed.
Veedrac - Thursday, May 28, 2020 - link
‘Tensor’ is a ML-ism for multi-dimensional arrays.Deicidium369 - Wednesday, May 27, 2020 - link
Tensor is a specific product from Google - made into systems and integrated into Nvidia's GPUs (Volta, Turing and Ampere). So while Nervana or Habana products that work in a similar way to Tensor cores, they ARE NOT Tensor cores.sun_burn - Thursday, May 28, 2020 - link
The TPU is a specific product range from Google. It is different from the GPU tensor cores in NVidia's Volta and subsequent architectures, though they may both be matrix multipliers.The former was originally a quantized 8-bit integer MAC engine, that later had (or will have ?) support for the bfloat16 datatype defined by Google.
The latter supports fp32, fp16 and since Turing, int8 and int4. Ampere also defines the new tf32 datatype.
kaidenshi - Wednesday, May 27, 2020 - link
Thank you, and I don't deny the impact "cloud" computing has had on the world in the past 20+ years. My day job relies on it, and I wouldn't want it any other way. My comment was specific to the whole buzzword phenomenon and nothing more.surt - Wednesday, May 27, 2020 - link
Neural PU.alicebcao75 - Monday, June 8, 2020 - link
Make 6150 bucks every month… Start doing online computer-based work through our website. I have been working from home for 4 years now and I love it. I don’t have a boss standing over my shoulder and I make my own hours. The tips below are very informative and anyone currently working from home or planning to in the future could use this website. WWW. iⅭash68.ⅭOⅯa
Stochastic - Wednesday, May 27, 2020 - link
Good write-up, but I think you mean to say "figuratively" in place of literally. We would be in trouble if there's a literal explosion of machine learning accelerators.